Privacidad
Introducción
Para enterarnos de las últimas noticias, para estar en contacto con nuestros amigos a través de las redes sociales o para comprar un bonito vestido, muchos de nosotros recurrimos a la web a la hora de buscar estos servicios e información en tan solo unos clicks. Un efecto colateral de pasarnos casi 7 horas al día en internet de media, es que muchas de nuestras actividades de navegación, y por lo tanto indirectamente también nuestros intereses y datos personales, son capturados o compartidos con una plétora de empresas y servicios web.
Mientras los anunciantes intentan ofrecer a los usuarios anuncios relevantes (con los que hay más probabilidades de que interactúen), a menudo recurren a rastreadores de terceros para deducir cuáles son los intereses del usuario. En resumen, la actividad online de un usuario es rastreada paso a paso, ofreciendo a los rastreadores, en particular a los más predominantes, un montón de información, la mayoría de la cual probablemente ni siquiera es relevante para deducir los intereses del usuario. Por si esto fuera poco, generalmente a los usuarios no se les da la posibilidad de no participar en esto adecuadamente.
En este capítulo exploraremos el actual estado de la web en cuanto a privacidad. Estudiamos la ubicuidad de los rastreadores de terceros, los diferentes servicios que conforman este ecosistema, y cómo algunos de ellos intentan sortear las medidas protectores que los usuarios emplean para proteger su privacidad (por ejemplo, listas de bloqueo anti-rastreadores). Además, también indagamos en cómo los sitios están intentando mejorar la privacidad de sus visitantes, adoptando funcionalidades que limiten la información compartida con otras entidades, o asegurándose de que cumplen leyes de privacidad como elGDPR y el CCPA.
Rastreo online
El rastreo (en inglés, “tracking”) es una de las tecnologías más generalizadas en la web: El 82% de las páginas web de escritorio (80% en móviles) incluyen por lo menos un rastreador de terceros. Siguiendo su comportamiento online, estas empresas de rastreo pueden crear perfiles de los usuarios, perfiles que luego usan para crear publicidad personalizada, para que los propietarios de los sitios web puedan saber y analizar quién los visita o para distinguir a los usuarios legítimos de los (no deseados) bots. En esta sección, exploraremos las diferentes técnicas empleadas para monitorizar la actividad de los usuarios online y cómo los rastreadores intentar evadir las diferentes funcionalidades diseñadas para evitar que los usuarios sean rastreados.
Rastreo de terceros
Uno de los métodos más comunes de rastreo online es emplear servicios de terceros; en el caso típico, el propietario del sitio inserta en su web un script de terceros que genera estadísticas y analíticas sobre el sitio o que muestra anuncios a los visitantes. Este script puede establecer en el navegador una cookie de terceros, y registrar así los sitios web que visita el usuario. Cuando el usuario visite otro sitio web que incluya el mismo servicio de terceros, la cookie se conectará con el rastreador, permitiendo reidentificar al usuario y vincular las dos visitas a ambas webs al mismo perfil.
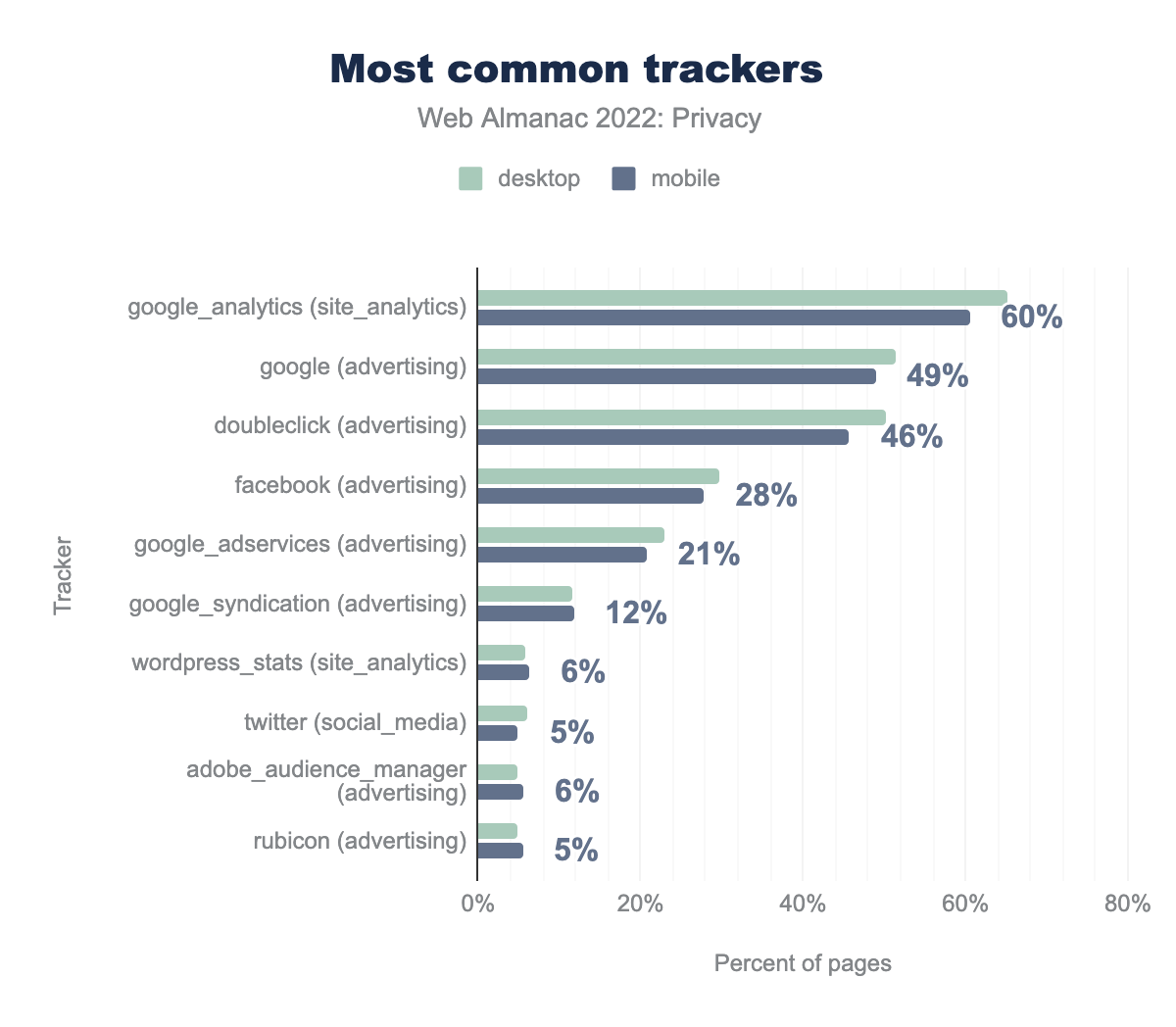
Los tipos de servicios de terceros que se insertan -y que por lo tanto tienen la capacidad implícita de rastrear a los visitantes del sitio web- varían un poco. Las dos categorías de rastreadores más comunes (tal y como las define WhoTracks.me) son los scripts de analítica (68% en móvil, 73% en escritorio) y los de publicidad (66% en móvil, 68% en escritorio). A ellos les siguen otras categorías de scripts que quizá no tengan una relación clara con el rastreo: interacción del cliente (servicios que le permiten al cliente enviar mensajes directos al dueño del sitio web), reproductores de audio / video (por ejemplo, vídeos de YouTube incrustados), y redes sociales (por ejemplo, los botones de “me gusta” de Facebook.
Para que un script de rastreo consiga crear perfiles de usuarios ha de estar insertado en una gran cantidad de sitios web desde los que rastrear una cantidad significativa de actividad online de usuarios. Si nos fijamos en los rastreadores más comunes, muchos de ellos son los “sospechosos habituales”. Entre los 10 rastreadores más comunes, cinco de ellos están afiliados a Google. En esta lista también se incluyen redes sociales muy populares como Facebook o Twitter.
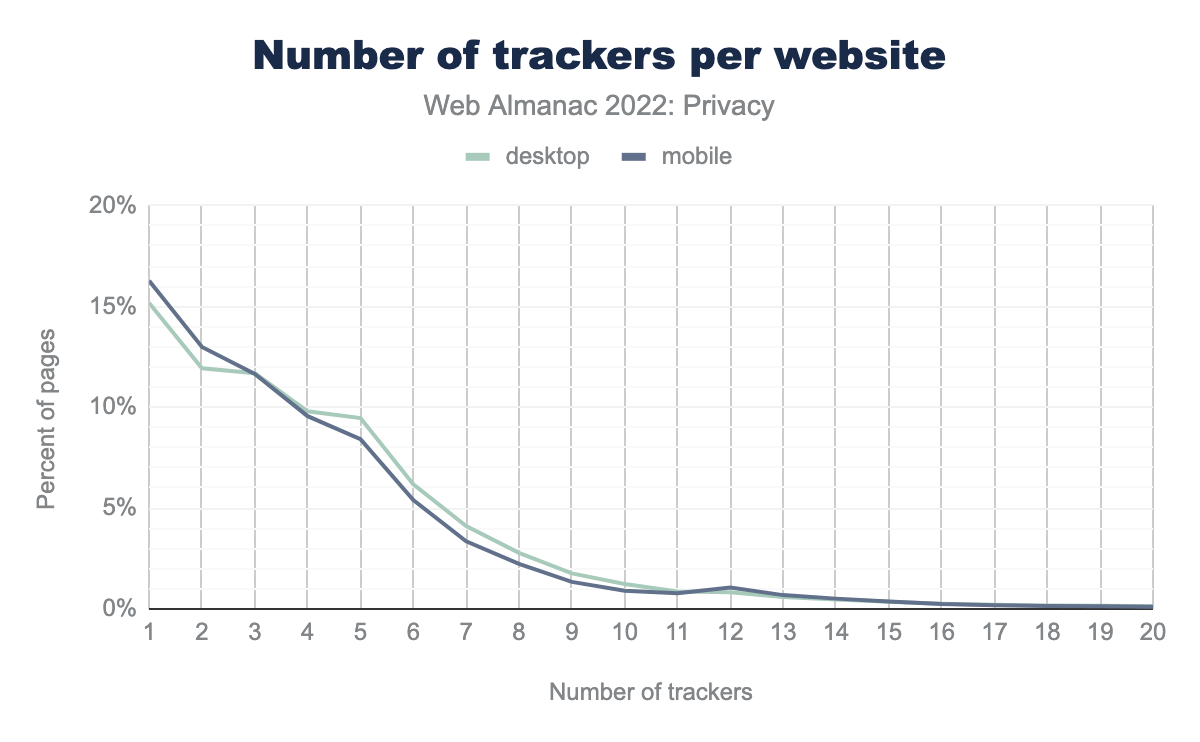
Los sitios web pueden emplear múltiples servicios de terceros y por lo tanto pueden tener insertados múltiples rastreadores (no dejes de revisar el capítulo de Terceros para conocer con detalle qué terceras partes están incluidas en la web). Descubrimos que aproximadamente el 15% de los sitios en escritorio y el 16% de los sitios en móvil incluyen “solo” un rastreador. Desafortunadamente, esto significa que de hecho es más común que los sitios webs incluyan varios rastreadores. ¡Incluso encontramos un sitio web que tenía insertados 126 rastreadores diferentes!
(Re)targeting
Cuando navegamos por la web, a menudo encontramos anuncios de productos que habíamos buscado recientemente. La razón es el retargeting (podría traducirse al español como “recaptación”). Cuando un sitio web detecta que un usuario podría estar interesado en un determinado producto, se lo notifica al rastreador y/o al anunciante, quienes más adelante, cuando el mismo usuario esté visitando otra página web no relacionada con la anterior, mostrarán anuncios del producto en el que supuestamente está interesado el usuario, intentando empujarlo hacia la compra.
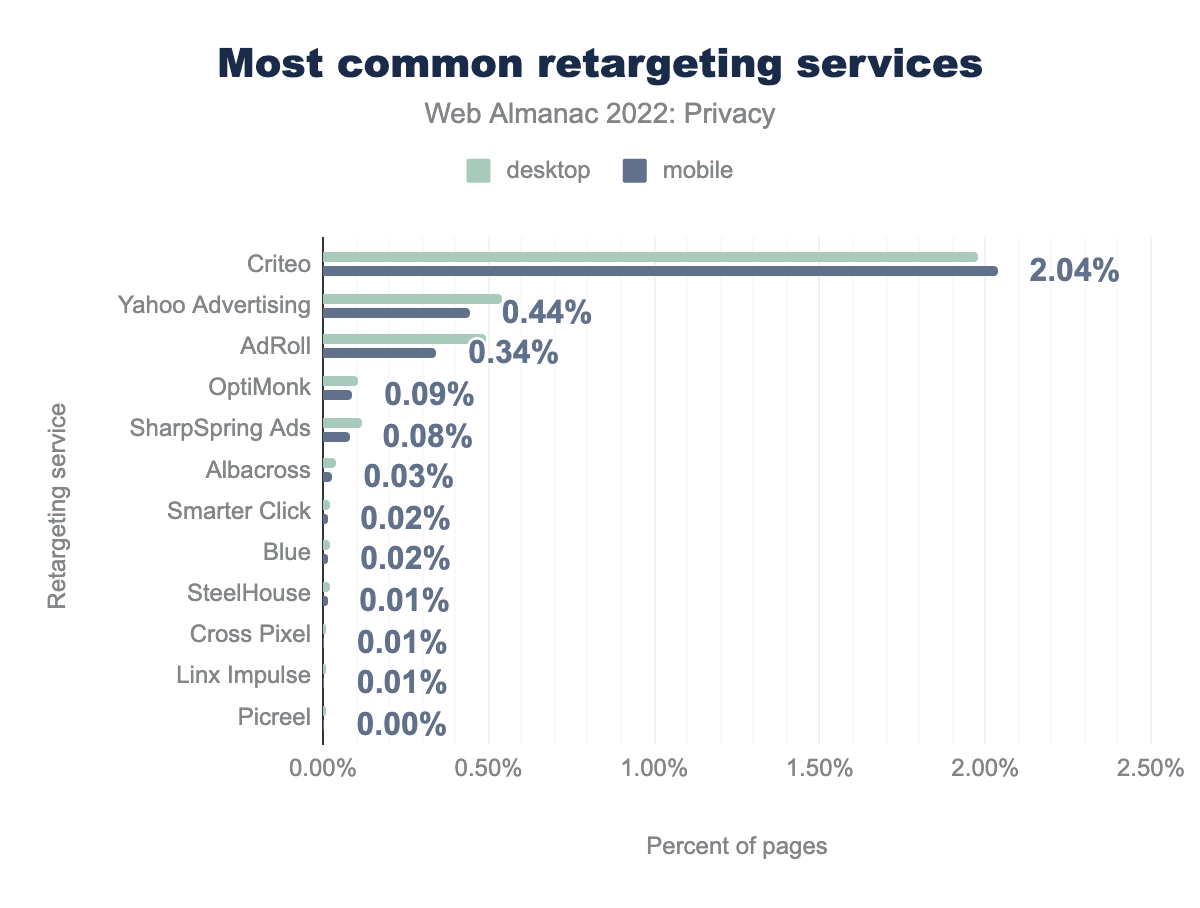
De los rastreadores que ofrecen servicios específicos de retargeting, el más común es Criteo, con una prevalencia del 1,98% en escritorio y del 2,04% en móvil. Lo sigue Yahoo Advertising y AdRoll, que juntos suman menos de la mitad de la cuota de mercado de Criteo. El servicio de retargeting que había sido el más ampliamente usado el año pasado, Google Tag Manager, no aparece en estos resultados porque ahora está clasificado dentro de la categoría de Wappalyzer “Gestores de etiquetas”. Aunque este servicio sí gestiona el retargeting, lo hace indirectamente, incluyendo etiquetas de retargeting que son detectadas de forma independiente.
Cookies de terceros
Como se comentó antes, la manera más establecida para rastrear a los usuarios a través de diferentes sitios web es empleando cookies de terceros. Con los recientes cambios en las políticas de los navegadores, las cookies ya no serán incluidas en las peticiones cross-site (entre diferentes sitios) por defecto. En términos técnicos, esto significa que la mayoría de los navegadores establecen el atributo SameSite de las cookies al valor por defecto Lax. Los sitios web pueden sobreescribir esto cambiando ellos mismos ese valor de forma explícita. Algo que ha esto ocurriendo a gran escala: de entre todas las cookies de terceros que establecen el atributo SameSite, el 98% de ellas le asignan el valor None, lo que les permite ser incluidas en las peticiones cross-site. Y aún hay más, en cuanto al tiempo de expiración que determina por cuánto tiempo la cookie es válida: descubrimos que el tiempo de vida medio de una cookie es 365 días. Para un estudio más a fondo de las cookies y sus atributos, por favor, revisa el capítulo Seguridad.
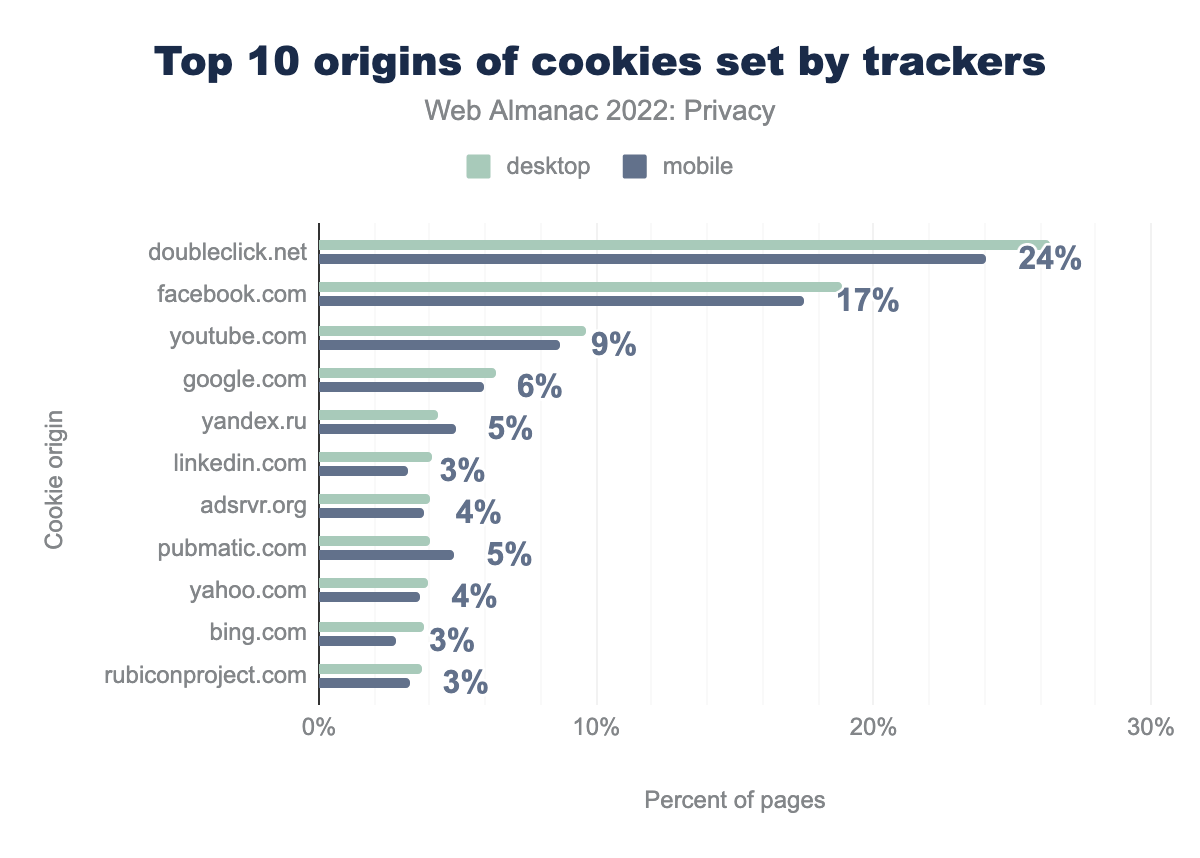
En gran medida, los rastreadores de terceros que crean cookies coinciden a grandes rasgos con los servicios terceros insertados en los sitios web. Sin embargo, el rastreador de terceros más común, Google Analytics, no tiene tanta prevalencia aquí. Esto se debe a que Google Analytics establece una cookie propia, o de origen, (_ga), que según su definición “es exclusiva de una propiedad específica, así que no se puede utilizar para rastrear a un usuario o navegador en sitios web no relacionados”. Aún así, el dominio de rastreadores que crean cookies de terceros más común, doubleclick.net, también es afiliado de Google. El resto de dominios que aparecen en la lista están vinculados a la publicidad y las redes sociales.
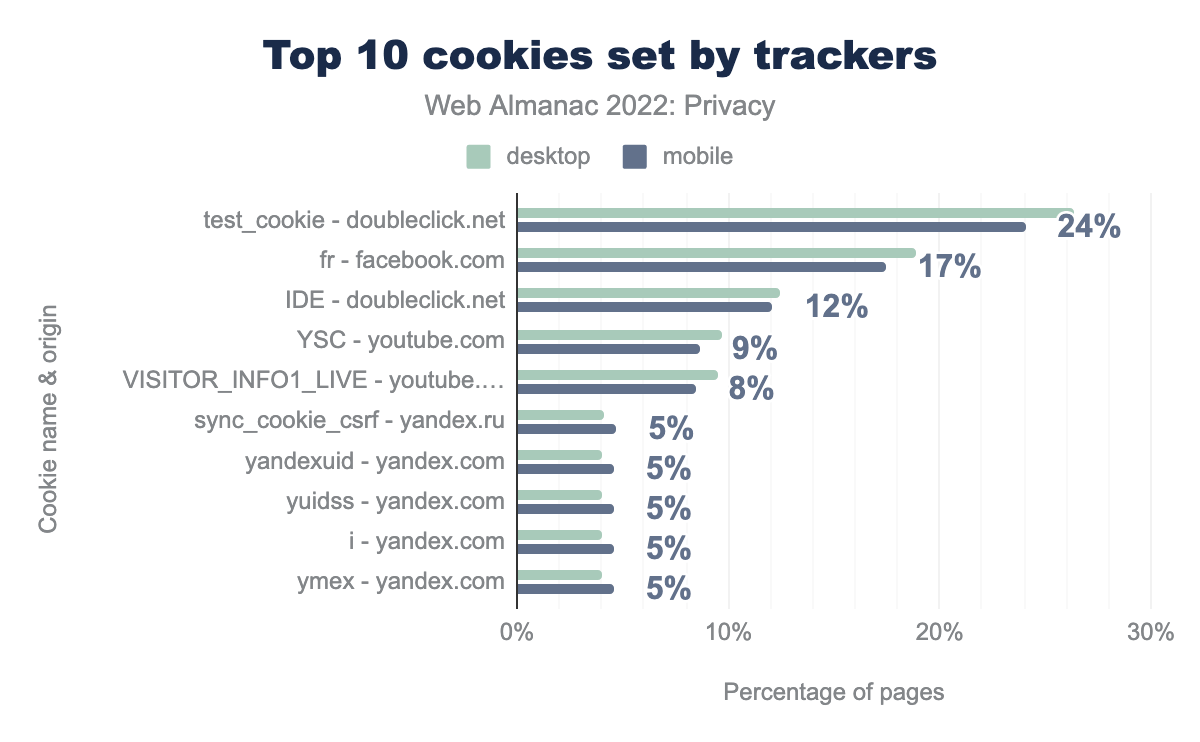
test_cookie, creada por doubleclick.net, se encuentra en el 26% de los sitios de escritorio y en el 24% de los sitios móviles; fr, creada por facebook.com, está presente en el 19% y el 17%, respectivamente; IDE, establecida por doubleclick.net, en el 12% y 12%; YSC, de youtube.com, en el 10% y el 9%; VISITOR_INFO1_LIVE, de youtube.com, en el 10% y el 8%; sync_cookie_csrf, originada en yandex.ru, en el 4% y el 5%; yandexuid, de yandex.com, en el 4% y 5%; yuidss, de yandex.com, en el 4% y 5%; i, de yandex.com, en el 4% y 5%, y por último ymex, creada también por yandex.com, en el 4% y 5%.Si nos fijamos en las cookies de terceros más comunes, volvemos a encontrarnos con varios dominios de rastreadores, empezando por la test_cookie de doubleclick.net—una cookie que dura 15 minutos y que es necesaria a nivel funcional según su descripción. A esta cookie la sigue la cookie fr procedente de facebook.com—una cookie empleada para “entregar, medir y mejorar la pertinencia de los anuncios, con una vida útil de 90 días”, según su definición. El resto de las 10 cookies más comunes provienen de YouTube y de Yandex.
Técnica de evasión: fingerprinting
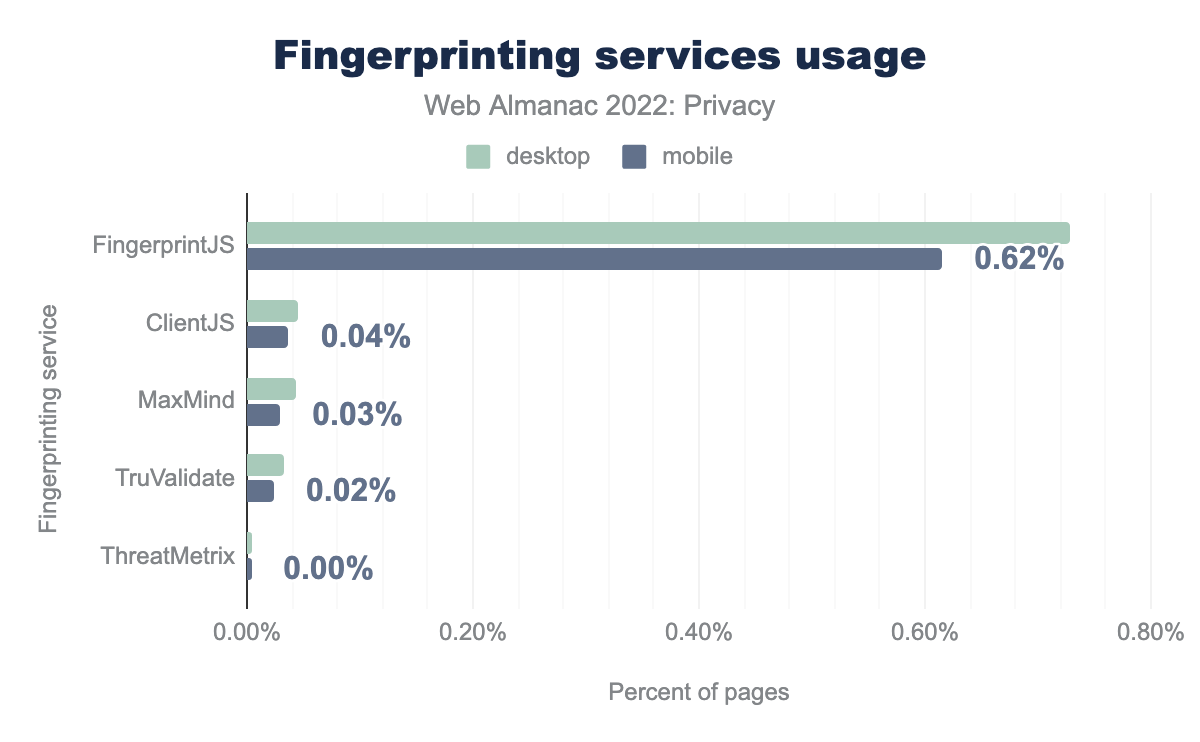
Mientras cada vez más navegadores desarrollan medidas contra el rastreo basado en cookies, dándoles a los usuarios más control para bloquear las cookies de terceros, algunos rastreadores intentan sortear estas protecciones. Una de estas técnicas de evasión es el seguimiento de las huellas digitales, más conocido por su nombre en inglés, fingerprinting: recurrir a características específicas de los navegadores (por ejemplo, las extensiones que hay instaladas), de los sistemas operativos (por ejemplo, las fuentes instaladas en el sistema) y del hardware (por ejemplo, las diferencias en el renderizado de composiciones complejas según qué GPU se esté usando) para crear una huella digital única del usuario. Esta huella permite que el rastreador pueda reidentificar al mismo usuario cuando visita sitios webs diferentes y no relacionados entre sí.
En nuestro análisis, buscamos cinco librerías diferentes y descubrimos que la más usada en la web para hacer fingerprinting es FingerprintJS, detectada en el 0.62% de todos los sitios web. Lo más probable es que esto se deba a que es una librería open source y con una versión gratuita. Comparado con nuestras métricas del año pasado, vemos que el uso del fingerprinting se ha mantenido más o menos igual.
Técnica de evasión: rastreo por CNAME
Dado que mucha de las medidas antirastreao se centrar en bloquear o deshabilitar las cookies de terceros, otra manera de evadir estas protecciones es emplear cookies propias o de origen en su lugar. En este caso, el rastreador se oculta usando el registro CNAME de un subdominio del sitio web en el que está insertado. Así, cuando el rastreador crea una cookie, será considerada como cookie propia. Una limitación de este rastreo basado en los CNAME es que sólo puede usarse para rastrear la actividad dentro de un sitio web específico, pero el rastreador podría recurrir a la técnica de sincronización de cookies para relacionar visitas a múltiples sitios.
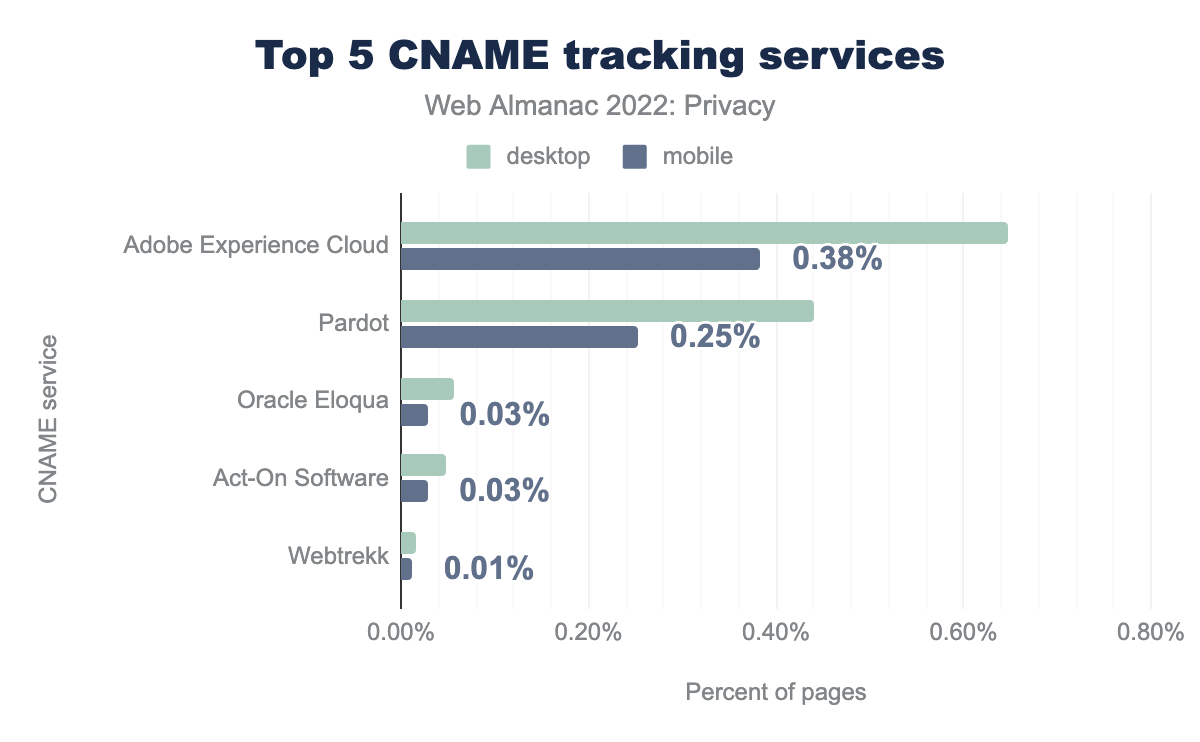
Analizando los diferentes rastreadores por CNAME, vemos que la cuota de mercado está concentrada en dos servicios principales: Adobe Experience Cloud (0,65% en escritorio y 0,38% en móvil) y Pardot (0,25% en escritorio y 0,44% en móvil). Curiosamente, la adopción del rastreo por CNAME es significativamente mayor en sitios visitados con un navegador de escritorio que en los visitados con un navegador móvil. Posiblemente esto se deba a que en móvil hay menos mecanismos para preservar la privacidad; por ejemplo, la mayoría de los navegadores para móvil no permiten instalar extensiones.
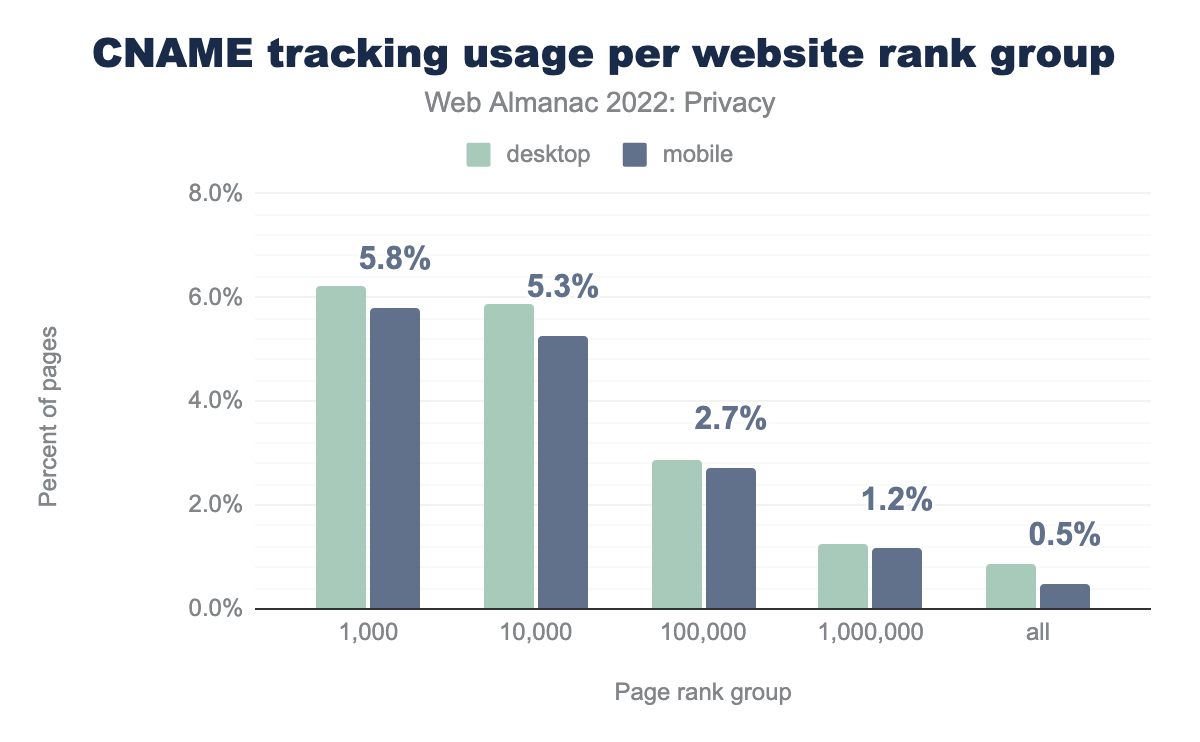
Aunque la prevalencia total de los rastreadores por CNAME puede parecer baja (0,9% en sitios para escritorio, 0,5% para móvil), su adopción está muy concentrada en sitios web muy populares. Dentro del top 1.000 de los sitios más visitados, el 6,2% de los de escritorio y el 5,8% de las versiones móviles tienen insertados un rastreador de tipo CNAME. Esto significa que es bastante probable que los usuarios se acaben encontrando con alguno de estos rastreadores mientras navegan por la web.
Acceso a datos (sensibles) desde el navegador
Los navegadores cuentan con un alto número de APIs que ofrecen a los desarrolladores mecanismos útiles para que puedan interactuar con diferentes componentes. Algunas de estas APIs también se pueden usar para extraer información de los sensores y otros periféricos conectados al dispositivo del usuario. Aunque la mayoría de las APIs ofrecen una cantidad limitada de información (como la orientación de la pantalla), otras ofrecen datos muy detallados (por ejemplo, el acelerómetro y el giroscopio) que pueden usarse para hacer fingerprinting de dispositivo, o incluso para deducir qué contraseña teclea un usuario basándose en los movimientos que hacen con su teléfono móvil.
Eventos de sensores
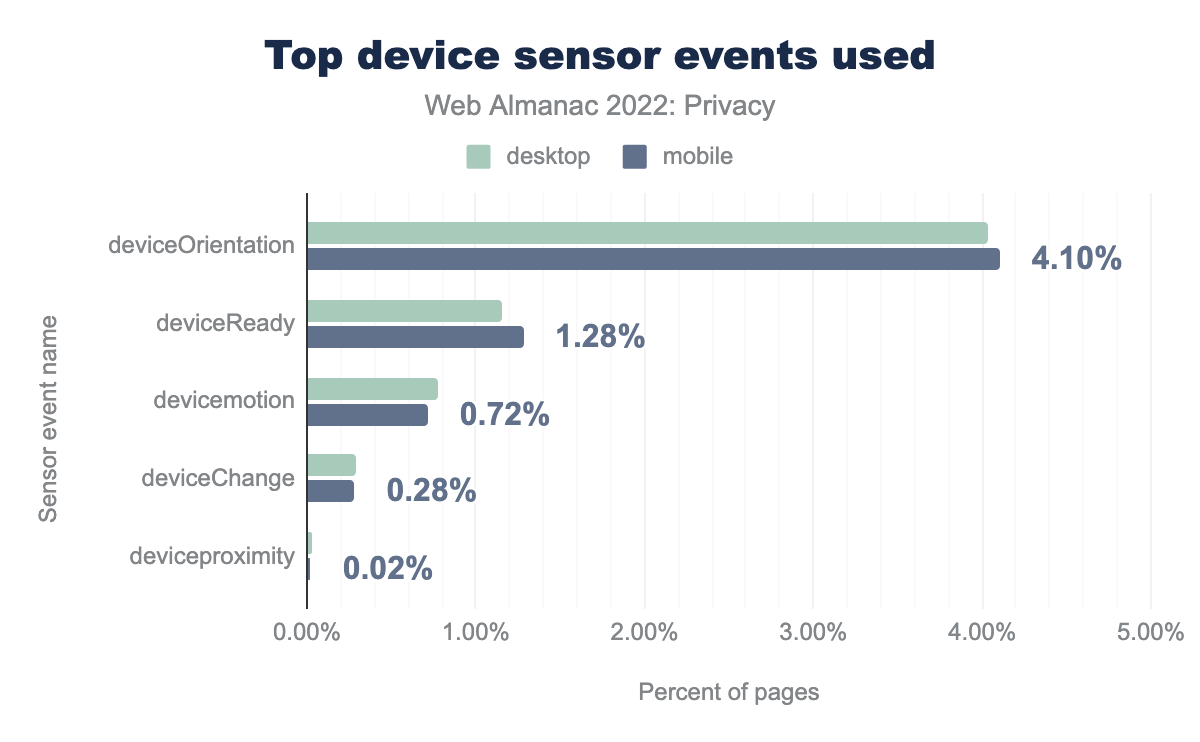
deviceOrientation se usa en el 4,04% de los sitios de escritorio y en el 4,10% de los sitios para móvil, deviceReady en el 1,16% y 1,28%, devicemotion en el 0,78% y 0,72%, deviceChange en el 0,29% y 0,28%, y por último el evento deviceproximity se detectó en el 0,03% de los sitios de escritorio y en el 0,02% de las versiones móvil.Descubrimos que el evento de sensores más monitorizado por los sitios web es el deviceOrientation, que se dispara cuando el dispositivo cambia de la vista horizontal a la vertical o viceversa. Se usa en el 4,0% de los sitios de escritorio y en el 4,1% de los sitios para móviles. Seguramente la razón de este uso sea que los sitios web puedan actualizar los elementos del diseño cuando cambia la orientación del dispositivo.
Dispositivos media
A través de la API MediaDevices, los desarrolladores web pueden usar el método enumerateDevices() para conseguir una lista de todos los recursos media conectados al dispositivo del usuario. Aunque esta funcionalidad puede ser útil para saber si un usuario tiene una cámara o un micrófono conectado a la hora de iniciar una videollamada, también se puede usar para recoger información sobre el entorno del sistema y usarla para hacer fingerprinting. Descubrimos que el 0.59% de los sitios de escritorio y el 0,48% de los sitios para móviles intentan acceder a la lista de recursos conectados -téngase en cuenta que nuestro crawler no interactúa con el sitio, ni hace click en ningún botón. Curiosamente, el uso de esta API se ha reducido significativamente desde el año pasado, cuando la prevalencia de sitios que acceden a la lista de recursos media era 12 veces mayor. Seguramente esto se deba al uso de una popular librería que funciona sin necesidad de hacer peticiones a la API.
Geolocalización
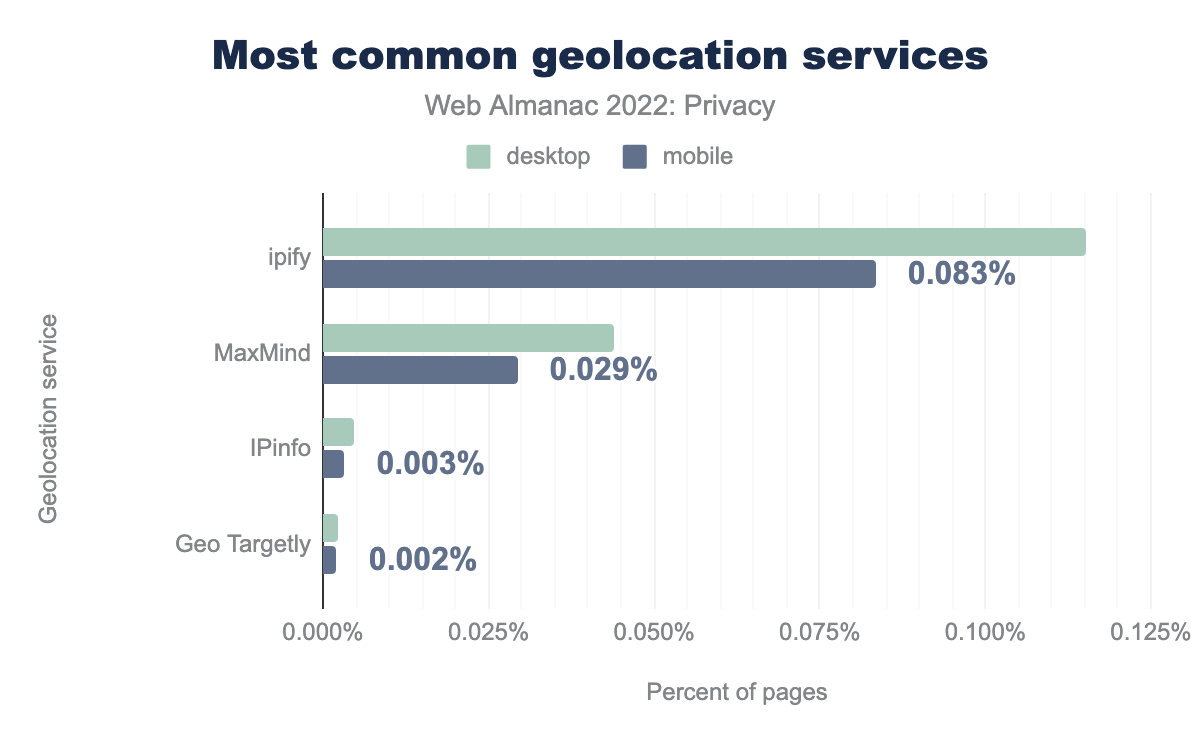
Buena parte del contenido que se nos sirve depende del lugar desde el que visitemos el sitio web. Para que los desarrolladores puedan determinar dónde está un usuario, pueden usar servicios de geolocalización de terceros. Estos determinarán la localización de un usuario basándose en su dirección IP. Aunque este tipo de geolocalización es más habitual en el bck-end, también detectamos algún uso en el front-end: el 0.115% de los sitios de escritorio y el 0.083% de los sitios para móviles se conectan con ipify para determinar la localización de la IP del usuario.
Aunque la geolocalización basada en la IP puede ser bastante imprecisa, sobre todo cuando los usuarios emplean una VPN para ocultar su dirección IP original, los sitios web pueden solicitar una localización más granular a través de la Geolocation API. Por supuesto, el acceso a esta API (intrusiva en cuanto privacidad) depende de que los usuarios den manualmente su permiso. Aún así, vemos que el 0,65% de los sitios de escritorio y el 0,61% de los sitios para móvil intentan acceder a la localización actual del usuario tras una visita a la página de inicio, sin que haya ninguna interacción del usuario. Curiosamente, aún detectamos 574 sitios de escritorio (menos que los 900 del año pasado) que intentaban acceder a esta funcionalidad cuando la página se cargaba a través de una conexión insegura. Debido a la naturaleza sensible de estos datos, la mayoría de los navegadores restringen su uso a orígenes seguros.
Controles establecidos para mejorar la privacidad del usuario
Dado que los sitios web incluyen mucho contenido de terceros (scripts, plugins, etc.) en el que no tienen por qué confiar plenamente, pueden proteger la privacidad de sus usuarios de estas terceras partes. A continuación exploraremos los diferentes controles que se pueden usar para restringir los datos o funcionalidades a los que tienen acceso los terceros, o para dejarles explícitamente claro qué información del usuario puede obtener un sitio web.
Política de Permisos
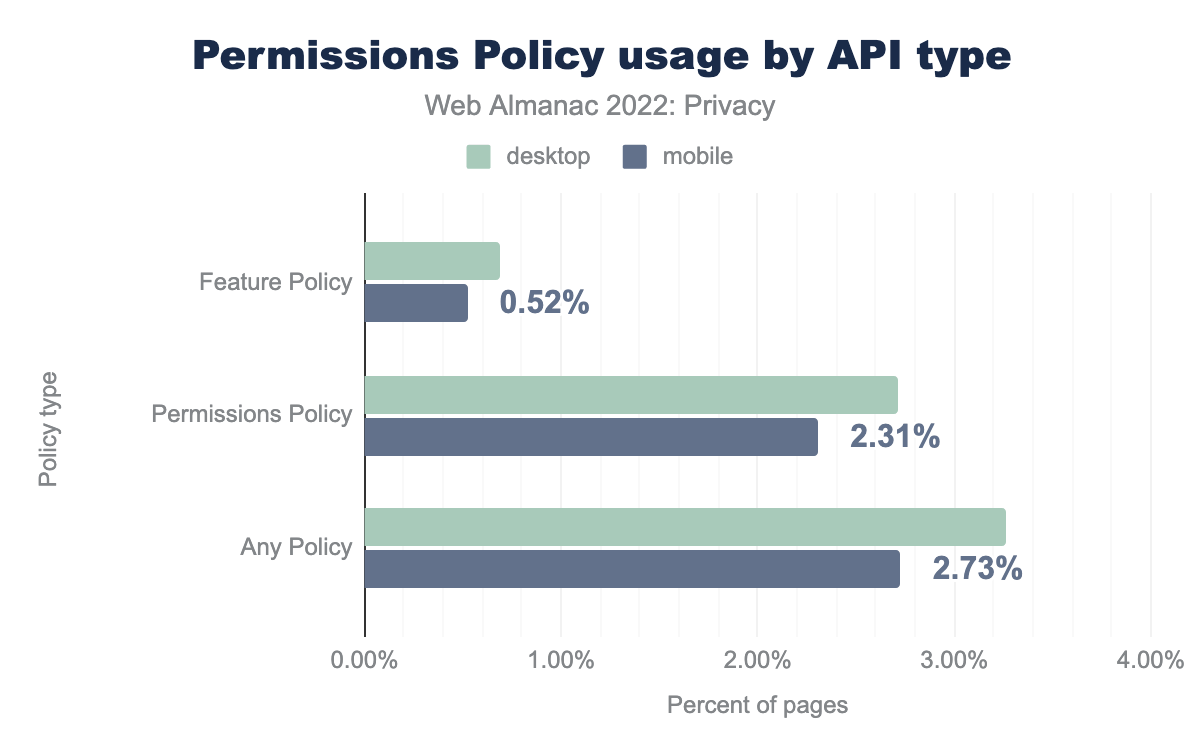
Por defecto, cualquier script de terceros puede acceder a las mismas funcionalidades que el sitio en el que está insertado. Para limitar las características que se habilitarán, el sitio web puede hacer uso de la Política de Permisos Política de Permisos. A través de un cabecero de respuesta HTTP el sitio web puede indicar qué funcionalidades quiere permitir. Por ejemplo, si la función microphone no está incluida en esta lista, ninguno de los scripts insertados en la página web puede usarla. Aunque esta política es bastante reciente, vemos una adopción del 2,71% de los sitios para escritorio y del 2,31% de los sitios en móvil.
La Política de Permisos (en inglés, “Permissions Policy”) sustituye a la Feature Policy (Política de Funcionalidades), que aún podemos encontrar en el 0,69% de los sitios de escritorio y en el 0,52% de los sitios móvil. Por defecto la mayoría de las características reguladas por la Política de Permisos están deshabilitadas en iframes de orígenes externos (cross-origin), pero pueden ser explícitamente habilitadas con el atributo allow. Vemos que el 15,18% de los sitios de escritorio y el 14,32% de los sitios móvil usan esta característica. Para un análisis más pormenorizado del uso del atributo allow en los iframes, por favor consulta el capítulo referido a la Seguridad.
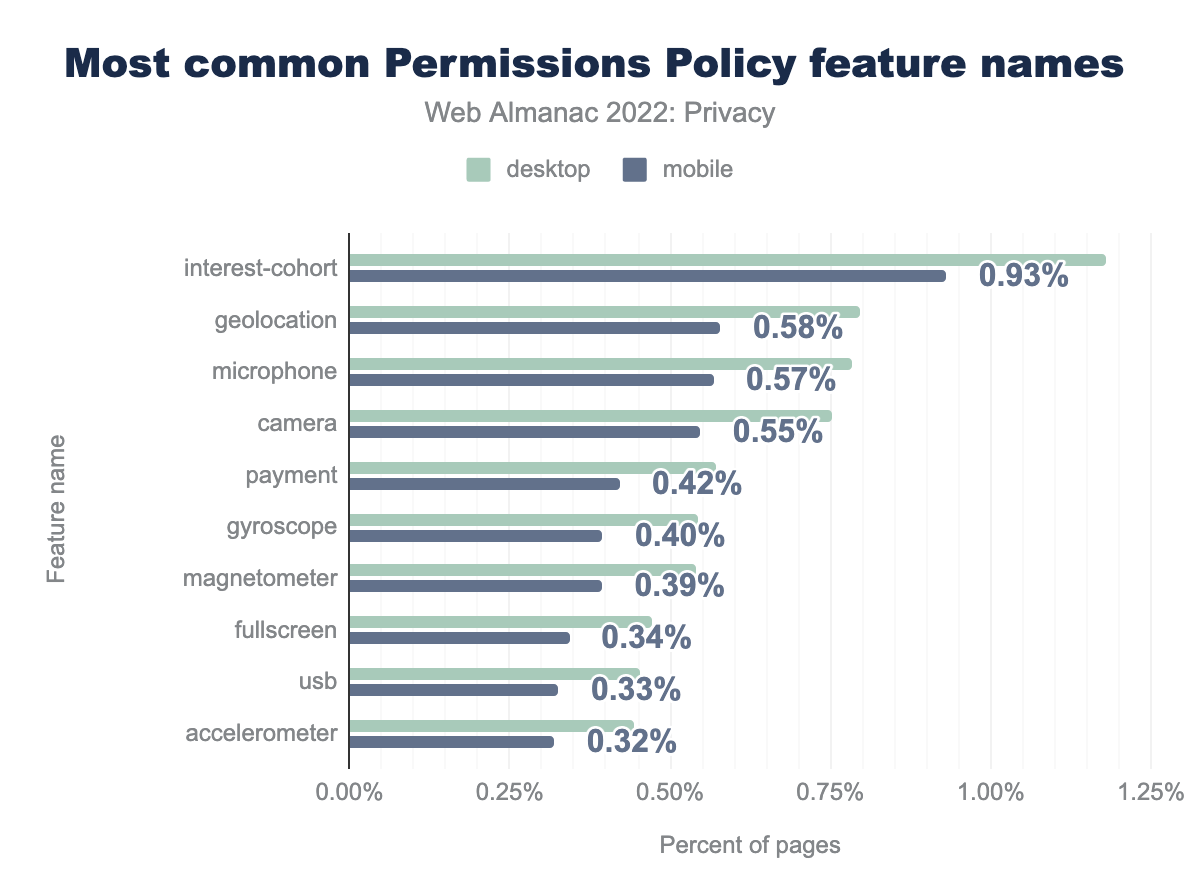
interest-cohort de la Política de Permisos estaba presente en el 1,18% de los sitios de escritorio y en el 0,93% de los móviles respectivamente, la característica geolocation se especificó en el 0,80% y 0,58% de los sitios, microphone en el 0,78% y 0,57%, camera en el 0,75% y 0,55%, payment en el 0.57% y 0,42%, gyroscope en el 0,54% y 0,40%, magnetometer en el 0,54% y 0,39%, fullscreen en el 0,47% y 0.34%, usb en el 0,45% y 0,33%, y por último accelerometer se detectó en el 0,44% de los sitios desde escritorio y en el 0,32% desde móvil.Si nos fijamos en qué directiva son las más usadas en la Política de Permisos, vemos un uso similar al del año pasado, con la excepción de la que ha sido la más usada en 2022, interest-cohort. Esta directiva puede usarse para limitar el acceso a la ahora difunta API FLoC. Probablemente este aumento se deba a los diferentes fallos de FLoC (aumento de la superficie de fingerprinting, revelación de información potencialmente sensible sobre los usuarios, etc.) que obligaron a los dueños de sitios web, proveedores y libreraías a tomar medidas para proteger la privacidad de sus usuarios.
Política de Referencias (Referrer Policy)
Por defecto, la mayoría de los agentes de usuario incluyen un cabecero Referer (referencia). Resumiendo, esto muestra a terceras partes desde qué sitio web -o incluso de qué pagina- se inició una petición. Esto se aplica para cualquier recurso que esté insertado en la página web, así como para la petición iniciada después de que un usuario haga click en un enlace. Por supuesto, una consencuencia indeseada de esto es que esas terceras partes sabrán qué sitio web, o incluso qué página web estaba visitando un usuario específico. Valiéndose de la Política de Referencias, los sitios web pueden limitar la instancias en las que el cabecero Referer se incluye en las peticiones y así mejorar la privacidad del usuario. in requests and thus improve user privacy. Observamos que el 12% de los sitios de escritorio y el 10-% de los sitios desde móvil establecen esta política en todo el documento, casi siempre a través de un cabecero de respuesta HTTP.
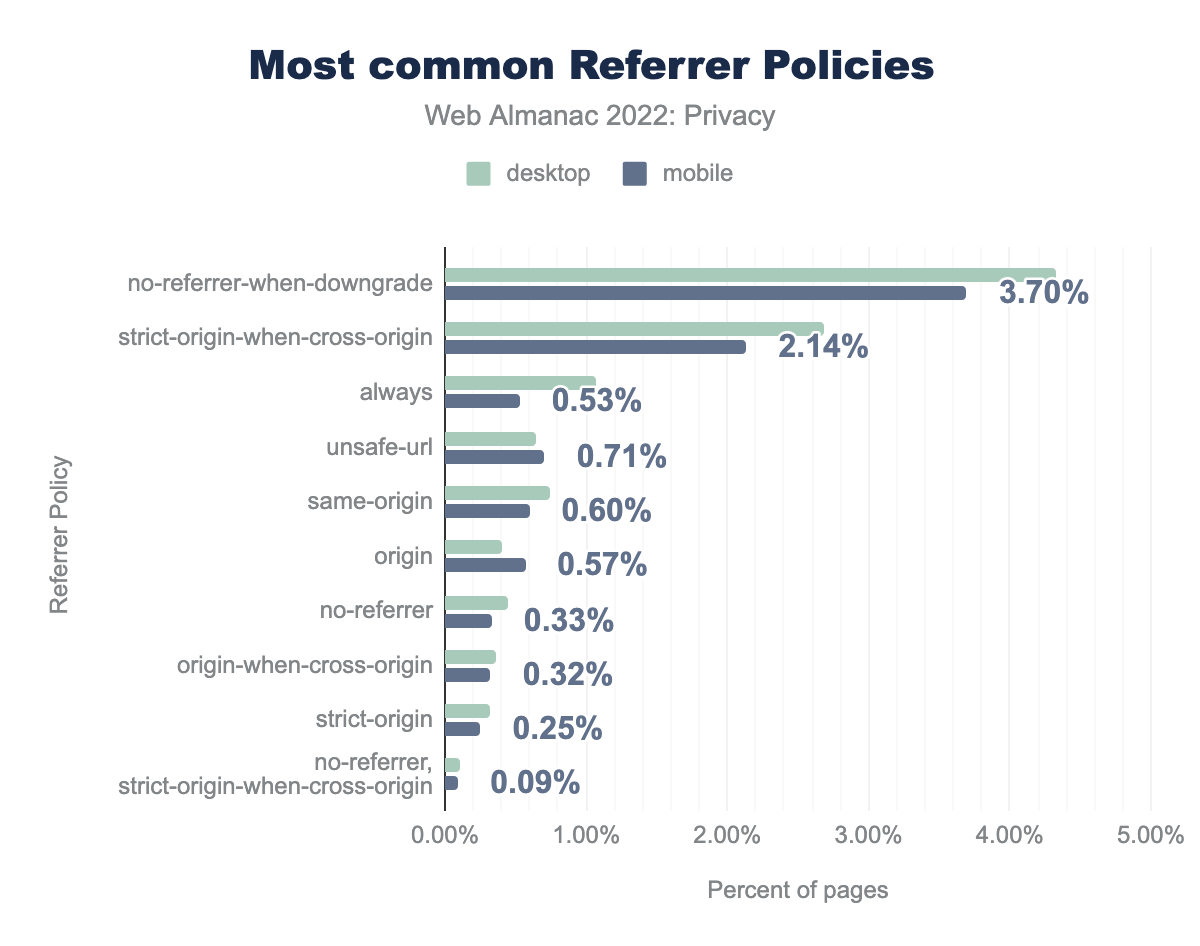
no-referrer-when-downgrade se encontró en el 4.33% de los sitios en escritorio y en el 3,70% desde móvil respectivamente, strict-origin-when-cross-origin se encontró en el 2,68% en escritorio y 2,14% en móvil, always en el 1,07% y 0,53%, unsafe-url en el 0,64% y 0,71%, same-origin en el 0,74% y 0,60%, origin en el 0,41% y 0,57%, no-referrer en el 0,44% y 0,33%, origin-when-cross-origin en el 0,37% y 0,32%, strict-origin en el 0,32% y 0,25%, y por último no-referrer, strict-origin-when-cross-origin se detectó en el 0,11% desde escritorio y en el 0,09% desde móvil.Vemos que el uso más común de Política de Referencias es no incluir el cabecero Referer en peticiones menos seguras, es decir, peticiones HTTP iniciadas en una página que tenga HTTPS habilitado. Desafortunadamente, con esto se sigue revelando la página que el usuario estaba visitando en la mayoría de los escenarios, que son los de las peticiones HTTPS. Sí vemos que el 2,7% de los sitios desde escritorio y el 2,1% desde móvil intentan ocultar la página web específica que el usuario está visitando a través de la política strict-origin-when-cross-origin, que ahora es la que eligen por defecto la mayoría de los navegadores cuando no especifica otra política.
Indicaciones del cliente sobre agentes de usuario (User-Agent Client Hints)
En un esfuerzo para reducir la cantidad de información que se revela sobre el entorno del navegador, y más específicamente la cadena User-Agent, se diseñó el mecanismo User-Agent Client Hints(en español, Indicaciones del cliente sobre el agente de usuario). Con este método, los sitios web que quieren acceder a cierta información sobre el entorno de navegación del usuario (versión del navegador, sistema operativo, etc.) ahora deben establecer un cabecero (Accept-CH) en la primera respuesta, y el navegador devolverá los datos solicitados en las siguientes peticiones. Entre otros beneficios, esta función reduce la superficie de huella digital (fingerprinting) y permite a los navegadores intervenir a la hora de enviar según qué datos, por ejemplo, con la propuesta del Privacy Budget (en español, Presupuesto de privacidad).
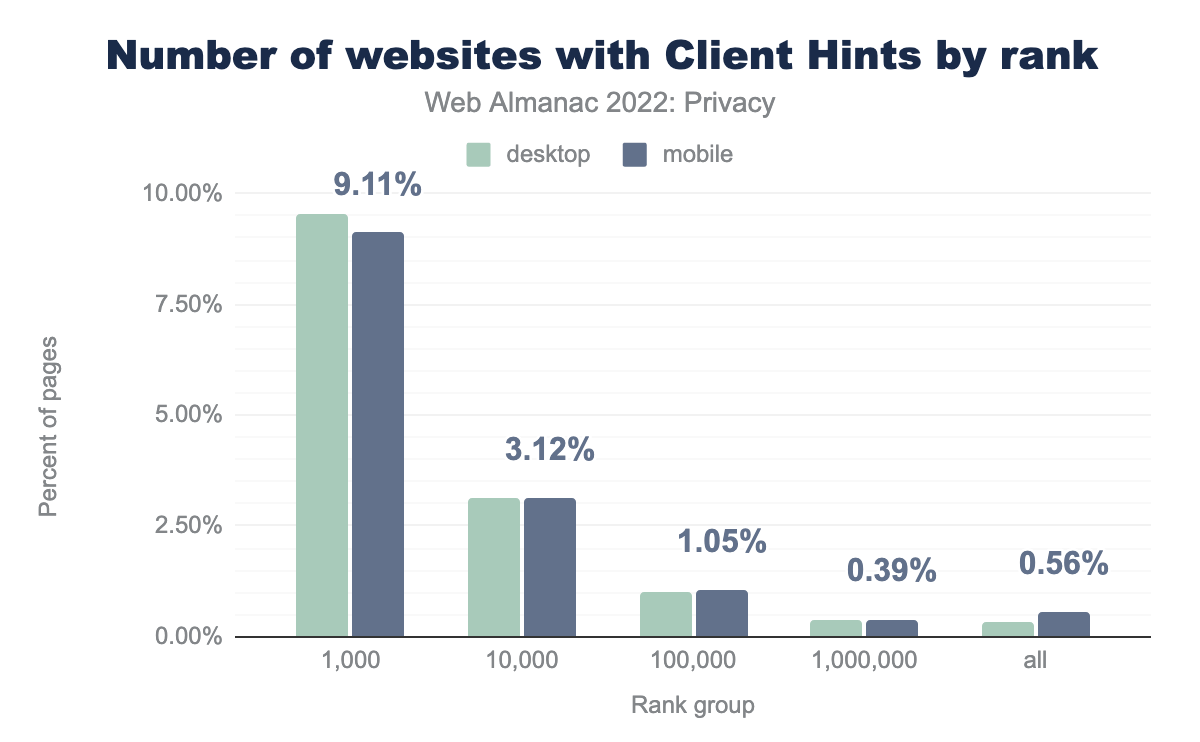
Si observamos el número de sitios que responden al cabecero Accept-CH en comparación con los resultados del año pasado (top 1.000: 3,56%, top 10.000: 1,44%), vemos un aumento significativo de la adopción de esta técnica, de casi tres veces más en los sitios más populares. we see a significant increase in adoption, almost 3x for the most popular sites. Presumiblemente, este aumento en la adopción está relacionado con el hecho de que Chromium ha estado reduciendo la información que comparte en la cadena User-Agent (mediante el Plan de Reducción del User-Agent).
Vemos que los sitios que emplean las Indicaciones de cliente sobre agentes de usuario generalmente solicitan acceso a una cantidad relativamente larga de propiedades, limitando así el beneficio que los navegadores pretenden conseguir con esfuerzos como el de la reducción de la cadena User-Agent. Será interesante ver cómo los navegadores intentarán en un futuro próximo seguir limitando las prácticas para adquirir información sobre el entorno de navegación del usuario.
Nuevos esfuerzos para mejorar la privacidad del navegador
Durante los últimos años, el usuario medio de la web se ha vuelto cada vez más consciente de su privacidad online. Por otro lado, las brechas y fugas de datos, que parecen ser cada vez más comunes y más graves, afectan a casi todo el mundo. A esto se suma que el rastreo ubicuo de usuarios a través de cookies de terceros ya es muy conocido entre la población general. Como resultado, cada vez son más los usuarios que esperan que su navegador proteja su privacidad y les dé más control sobre el rastreo de comportamientos online. Los fabricantes de navegadores, los creadores de contenido online y las compañías de publicidad se han hecho eco de esta demanda para mejorar la privacidad y han propuesto la Privacy Sandbox, una iniciativa encabezada por Google Chrome.
Prueba de origen en Privacy Sandbox
En el momento de publicar el Web Almanac de este año, las funcionalidades de la Privacy Sandbox (en español, “Entorno de privacidad”) aún no están disponbiles para el uso general. Sin embargo, los sitios y servicios web -como por ejemplo los anuncios, que suelen mostrarse en iframes- pueden participar en el testeo adelantado de las características de la Privacy Sandbox, usando la Prueba de origen (en inglés, “Origin Trial”). Hay que tener en cuenta que esto sólo se aplica a los usuarios cuyo navegador soporta las característias de la Privacy Sandbox, y que éstas sólo están implementadas en Chrome y desactivadas por defecto en el momento de escribir este informe. La Prueba de origen les da a los servicios web acceso a tres APIs diferentes relacionadas con la Privacy Sandbox: Topics, FLEDGE y Informes de atribuciones.
| Origen que solicita funcionalidad | Escritorio | Móvil |
|---|---|---|
| https://www.googletagmanager.com | 12,53% | 10,99% |
| https://googletagservices.com | 11,05% | 10,52% |
| https://doubleclick.net | 11,04% | 10,51% |
| https://googlesyndication.com | 11,04% | 10,51% |
| https://googleadservices.com | 2,50% | 2,29% |
| https://s.pinimg.com | 1,49% | 1,21% |
| https://criteo.net | 0,64% | 0,41% |
| https://criteo.com | 0,59% | 0,37% |
| https://imasdk.googleapis.com | 0,10% | 0,07% |
| https://teads.tv | 0,04% | 0,03% |
Los servicios más habituales de los que testearon la Privacy Sandbox a través de la Prueba de origen fueron: Google Tag Manager, Doubleclick, Google Syndication y Google Ad Services, que están en el top 5 tanto en escritorio como en móvil. Los sigue la red social Pinterest y otros rastreadores y anunciantes: Criteo, Google Ads SDK y Teads.
Experimentos en la Privacy Sandbox
La iniciativa Privacy Sandbox consiste en muchas funcionalidades diferentes que cubren diferentes aspectos y cuyo objetivo es seguir dando soporte a las acciones más comunes de los usuarios en la web a medida que el sistema de las cookies de terceros va desapareciendo. Dado que la mayoría de las funcionalidades aún están en fase de desarrollo, los sitios web aún no las han adoptado (con la excepción de los servicios que soclitiaron acceso a la PrivacySandboxAdsAPIs a través de la Prueba de origen).
Durante un tiempo, la Prueba de origen para diferentes funcionalidades de la Privacy Sandbox se separó en diferentes pruebas o “trials”, una para cada funcionalidad. Aunque estas pruebas no tienen ningún efecto en los entornos de navegación modernos, algunos servicios web sí que solicitaron acceso y se olvidaron de eliminar el cabecero de respuesta Origin-Trial.
Por ejemplo, vemos que en 34,128 sitios un servicio web accede a la Prueba de Origen del ConversionMeasurement , que en algún momento les dio acceso a la API Informes de atribución (previamente llamada API de Medición de Conversiones). Esta API se usa, por ejemplo, para rastrear las conversiones de los usuarios que hacen click en un anuncio.
Para la Prueba de origen TrustTokens, que también ha expirado, aún vemos 6.005 sitios en los que un servicio web solicita acceso. Este mecanismo intenta ayudar a los sitios web a combatir el fraude permitiendo que un contexto de navegación (por ejemplo, un sitio) transmita una cantidad limitada de información a otra.
Es interesante destacar que en más de 30.000 sitios web un servicio web aún está intentando acceder a la Prueba de origen InterestCohort, que les daría acceso al grupo de interés del usuario en FLoC. Sin embargo, debido a las dudas que esta API generó respecto a la privacidad, se interrumpió su desarrollo. Fue sustituida por la the API FLEDGE, que intenta ofrecer “subastas de anuncios en el dispositivo de forma local para ayudar al remarketing y a las audiencias personalizadas” y la API Topics API, cuyo objetivo es permitir que los anunciantes sirvan anuncios basados en los intereses del usuario sin necesidad de recurrir al rastreo en diferents sitios web.
Cumplimiento de las regulaciones de privacidad
El espacio de regulación de la privacidad continúa creciendo como la frontera más reciente de la legislación. Estas regulaciones requieren que las organizaciones sean más transparentes a la hora de procesar los datos de sus usuarios para protegerlos. Tras la aprobación de leyes de privacidad clave como el Reglamento General de Protección de Datos y Framework de Transaprencia y Consentimiento IAB (TCF) v2.0, los proveedores de páginas web se pusieron manos a la obra para informar a sus usuarios sobre cómo se procesan sus datos durante la visita, recogiendo el consentimiento de estos usuarios para procesar sus datos también con fines no funcionales, como por ejemplo, analítica y anuncios. Por esta razón vemos en las webs cada vez más banners de cookies, el sistema más empleado por los sitios webs para notificar a sus usuarios o pedirles su consentimiento.
En la mayoría de los casos, los usuarios pueden interactura con estos banners y elegir qué datos pueden ser procesados. Sin embargo, gestionar esas tareas no es sencillo en nuestra moderna y sofisticada web, que cada vez se hace más compleja. Por ello, muchos operadores de sitios web delegan este trabajo en terceras partes, llamadas Plataformas de Gestión del Consentimiento (CMP, por sus siglas en inglés). Las CMP se aseguran de que las cookies se emplean correctamente en la web, según lo que dicta la ley. A continuación desgranamos el uso de CMP y de las notificaciones de políticas de privacidad.
Plataformas de Gestión del Consentimiento (CMP)
Como hemos visto, emplear una Plataforma de Gestión del Consentimiento debería garantizar que el sitio web, en particular el comportamiento de las cookies, funciona de acuerdo a la ley.
Aquí debemos señalar que el uso de estos servicios de CMP no siempre garantiza que los sitios webs cumplan la ley, tal y como muestran varios siguientes estudios (por ejemplo Santos et al. y Fouad et al.).
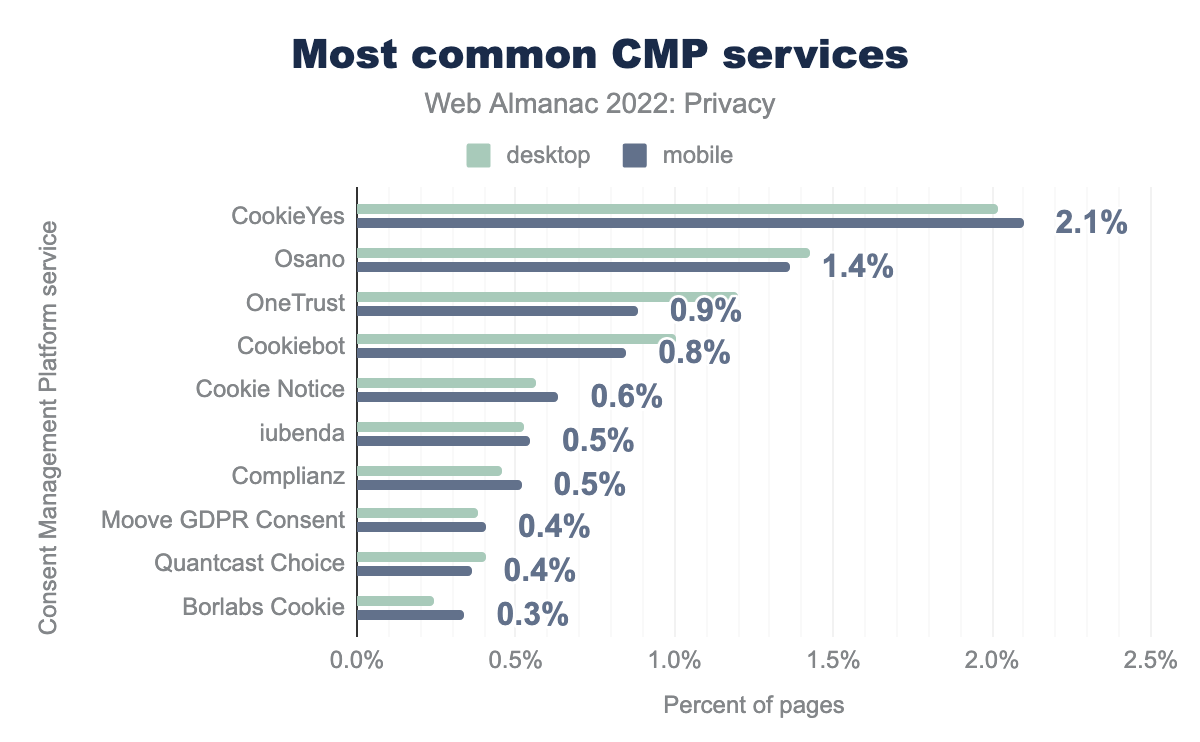
Nuestro análisis muestra que el uso de CMP ha aumentando del 7% al 11% desde el año pasado. Un aumento de casi el 60%. Además, también vemos que este año el móvil está menos implicado que el escritorio, aunque la diferencia es mínima. También vems que los proveedores CookieYes (18%), OneTrust (64%) y Cookiebot (56%) han aumentado su cuota de mercado desde el año pasado.
Frameworks de consentimiento IAB
Al contrario que el GDPR, el Framework de Transparencia y Consentimiento IAB Europe (TCF) es un estándar de la industria en el que están implicados comerciantes globales. El objetivo es establecer comunicación entre el consentimiento del usuario y los anunciantes. El TCF garantiza que los sitios web de Europa cumplen en l GDPR. El IAB Tech Lab US desarrolló las U.S. Privacy Technical Specifications (USP) para que los sitios de Estados Unidos usen el mismo concepto de TCF.
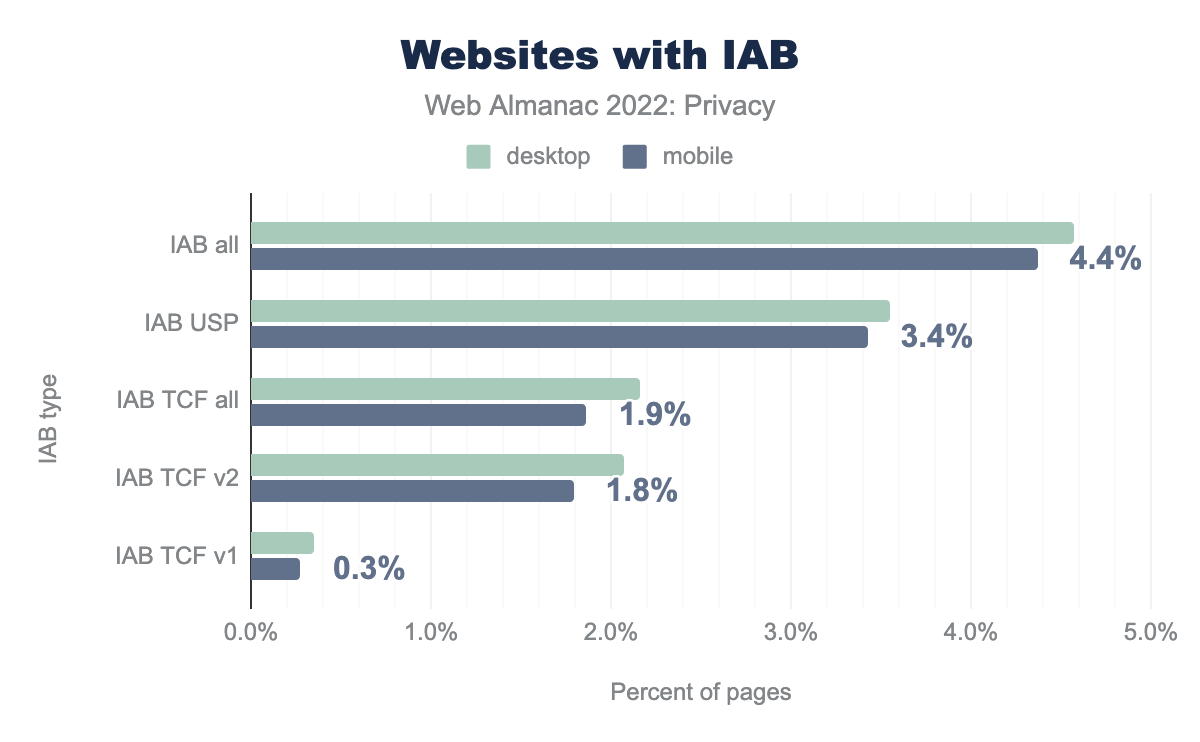
Descubrimos que el 4,6% de los sitios en escritorio usan algún IAB, con el 3,5% usando USP y el 2,2% usando IAB. Se trata de un aumento del uso desde el año pasado. Queremos destacar que nuestras mediciones se hacen desde EEUU, por lo que según TCF, no es necesario mostrar ningún banner de consentimiento para las visitas que no provienen de la Unión Europea. Quizá sea esa la razón por la que identificamos más sitios con USP.
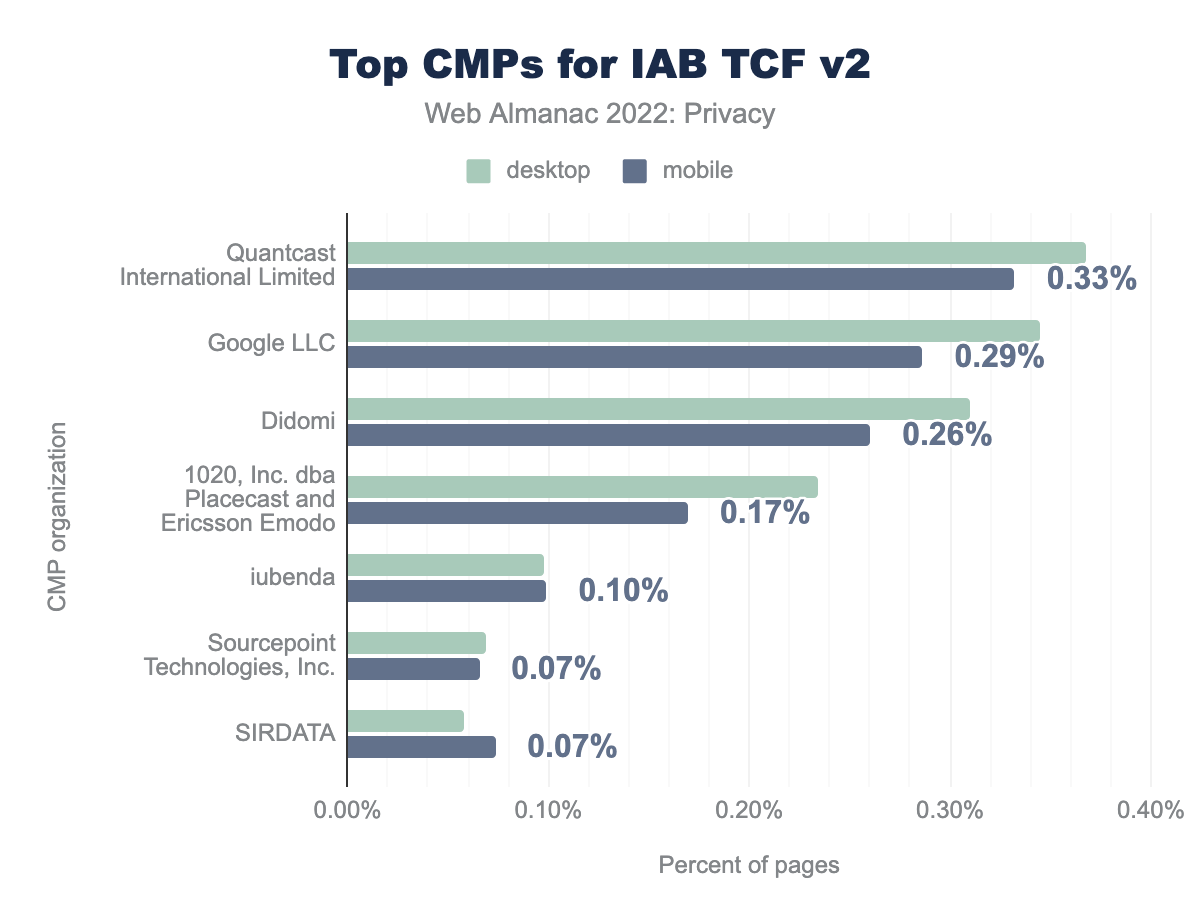
Vemos que Quantcast International Limited (0.37%), Google LLC (0.34%) y Didomi (0.31%) son servicios CMP populares para IAB TCF v2.
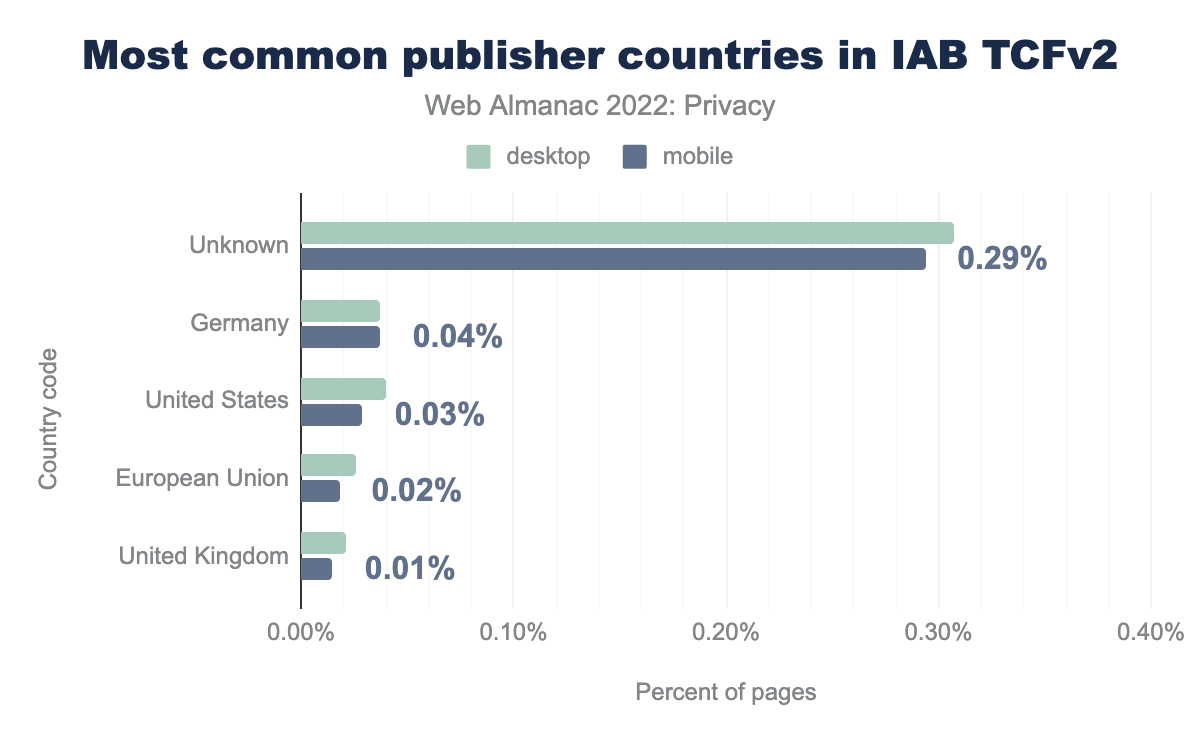
Nuestro análisis muestra que la mayoría de los editores identificados eran de Alemania, EEUU y la UE..
Política de privacidad
Las notificaciones relacionadas con el procesamiento de datos no siempre se ubican en un banner de consentimiento. También suelen describirse con más detalle en páginas separadas. En estas páginas, se muestra información sobre los servicios de terceros empleados, qué información es empleada para cada fin, etc. Para identificar estas páginas, empleamos las señales relacionadas con la privacidad indicadas en este estudio. Con este método, pudimos determinar que el 45% de los sitios desde escritorio (el 41% en móvil) contenía un enlace en su página inicial a una página relacionada con la privacidad. El siguiente gráfico muestra la distribución de las palabras contenidas en este enlace.
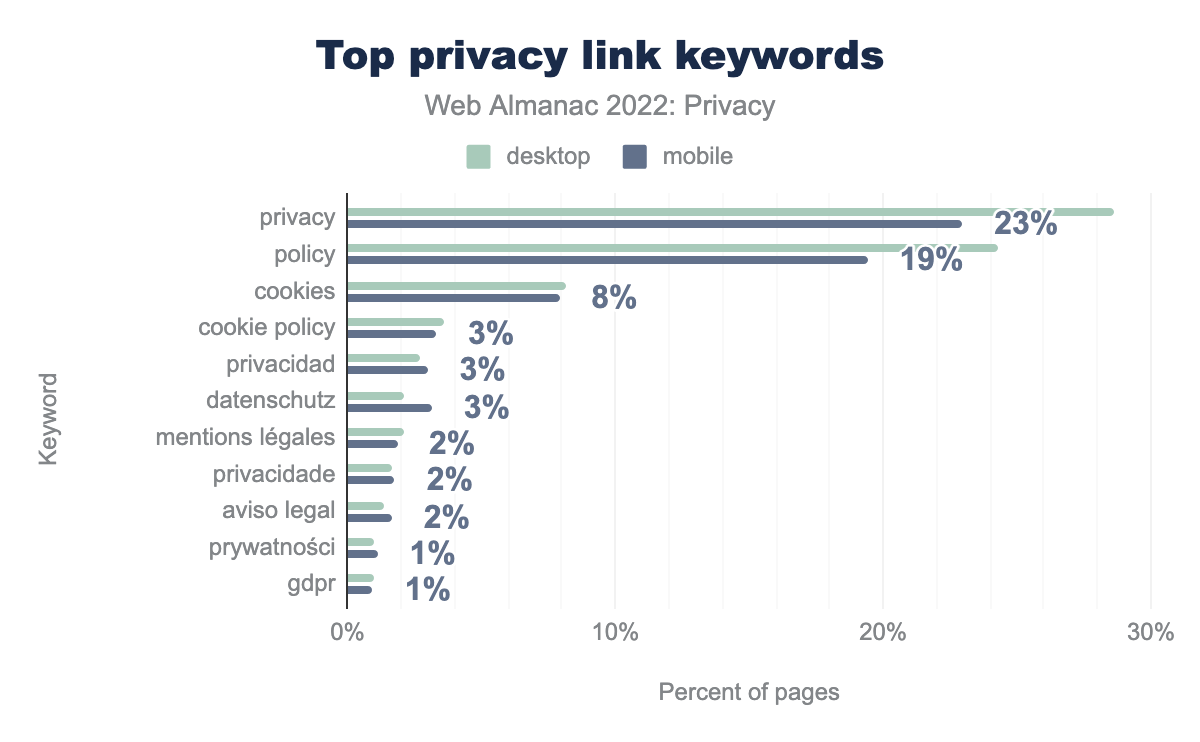
Vemos que “privacy” (29%), “policy” (24%) y “cookies” (8%) son las palabras más usadas en esos enlaces.
Conclusión
En este capítulo, exploramos diferentes aspectos relacionados con nuestra privacidad online. Está claro que durante el pasado año cambiaron bastantes cuestiones que afectan a nuestra privacidad, y podemos esperar que este progreso continúe en los próximos años. Resumiendo, creemos que están por llegar cosas interesantes. Por un lado, vimos evoluciones desafortunadas, que esperemos que algún día no sean más que el pasado de la web. Rastreo de terceros, basado fundamentalmente en las cookies de terceros, aún es ubicuo: el 82% de los sitios web contienen al menos un rastreador. Además de esto, hay un número considerable de sitios o servicios web que emplean técnicas evasivas para eludir las medidas anti-rastreo.
Desde una perspectiva más positiva y pro-privacidad, vemos que hay menos sitios que tratan de acceder a información potencialmente sensible desde las APIs de nuestros navegadores. Confiemos en que este siga siendo el caso con las nuevas APIs de navegación que se están introduciendo.
Generalmente, parece que los sitios web están empezando a hacerse eco de las demandas de los usuarios con respecto a su privacidad, una demanda que cada vez es más fuerte. Cada vez hay más sitios que empiezan a usar funcionalidades del navegador para restringir la información que se envía a terceros. Además, motivados mayormente por leyes de privacidad como el GDPR y el CCPA, hemos visto un claro aumento —casi un 60%— en el uso de Plataformas de Gestión del Consentimiento, dando a los usuarios más control sobre qué información quieren compartir.
Finlamente, del lado de los navegadores, también vemos una fuerte evolución dirigida a ofrecer a los usuarios más control sobre su privacidad online. Junto con las funcionalidades que ya ofrecen varios navegadores especializados en privacidad, también está la iniciativa Privacy Sandbox que intenta seguir ofreciendo funcionalidades como publicidad dirigida, antifraude, atribución de compras, etc. sin el nefasto efecto secundario del rastreo a través de múltiples sitios. Aunque su desarrollo aún está en fase muy temprana, vemos que un número sustancial de sitios web ya están solicitando acceso a esta iniciativa a través de la Prueba de origen. Así, estas novedades se pueden testear de forma extensiva y tener más posibilidades de convertirse en una parte persistente de la web.
Aunque aún tardaremos un par de años en llegar ahí, estamos evolucionando hacia una web que da a los usuarios más control sobre lo que quieren compartir con terceros. Vemos esta convergencia en ambos lados del espectro; por un lado iniciada por el sitio web y por el otro forzada por el navegador. Con la esperanza de un mañana más respetuoso para todos, debemos confiar en que en un futuro no muy lejano los datos que compartimos serán los datos que queremos compartir y en que las rutas que seguimos día a día cuando navegamos por la web ya no serán recogidas, compartidas y analizadas por los numerosos rastreadores que hoy en día encontramos.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}