SEO
序章
SEO (Search Engine Optimization) は、検索エンジンのオーガニック検索結果からのトラフィックの量と質を高めるために、ウェブサイトやウェブページを最適化することです。
SEOはかつてないほど人気があり、企業が顧客にアプローチする新しい方法を模索する中で、ここ数年大きな成長を遂げています。SEOの人気は、他のデジタルチャネルをはるかにしのいでいます。
Web AlmanacのSEOの章の目的は、Webサイトの最適化に関連するさまざまな要素を分析することです。この章では、Webサイトがユーザーと検索エンジンに優れた体験を提供しているかどうかをチェックします。
分析には、Lighthouse、Chrome User Experience Report (CrUX) 、モバイルとデスクトップの HTTP Archive から得られる生とレンダリングのHTML要素を含む多くのデータが使用されました。HTTP ArchiveとLighthouseの場合、サイト全体のクロールではなく、ウェブサイトのホームページのみから特定されるデータに限定されます。このことを念頭に置いて、私たちの結果から結論を出してください。分析の詳細については、方法論のページでご覧いただけます。
Webの現状と検索エンジンの利便性については、こちらをご覧ください。
クロール性とインデックス性
このようなユーザーの問い合わせに対して適切な結果を返すために、検索エンジンはウェブの索引を作成する必要がある。そのためのプロセスには
- クローリング - 検索エンジンは、ウェブクローラー(スパイダー)を使ってインターネット上のページを巡回しています。スパイダーは、サイトマップやページ間のリンクなどの情報源から新しいページを見つけます。
- 処理 - このステップでは、検索エンジンがページのコンテンツをレンダリングすることがあります。検索エンジンはインデックスを作成・更新し、ページをランク付けし、新しいコンテンツを発見するために使用するコンテンツやリンクなど、必要な情報を抽出します。
- インデックス作成 - コンテンツの品質と独自性に関する一定のインデックス作成要件を満たしたページは、通常、インデックスに登録されます。インデックスされたページは、ユーザーのクエリに対して返される資格があります。
ここでは、クローラビリティとインデックス作成に影響を与える可能性のある問題をいくつか見てみましょう。
robots.txt
robots.txt とは、ウェブサイトの各サブドメインのルートフォルダーに置かれるファイルで、検索エンジンのクローラーなどのロボットへどこに行ってよいか、どこに行ってはいけないかを伝えるためのものです。
81.9%のWebサイトがrobots.txtファイル(モバイル)を活用している。前回(2019年72.2%、2020年80.5%)と比較すると、やや改善されたことになります。
robots.txtの作成は必須でありません。404 not foundを返している場合、Googleはウェブサイトのすべてのページがクロールできると仮定しています。他の検索エンジンでは、これとは異なる扱いを受ける可能性があります。
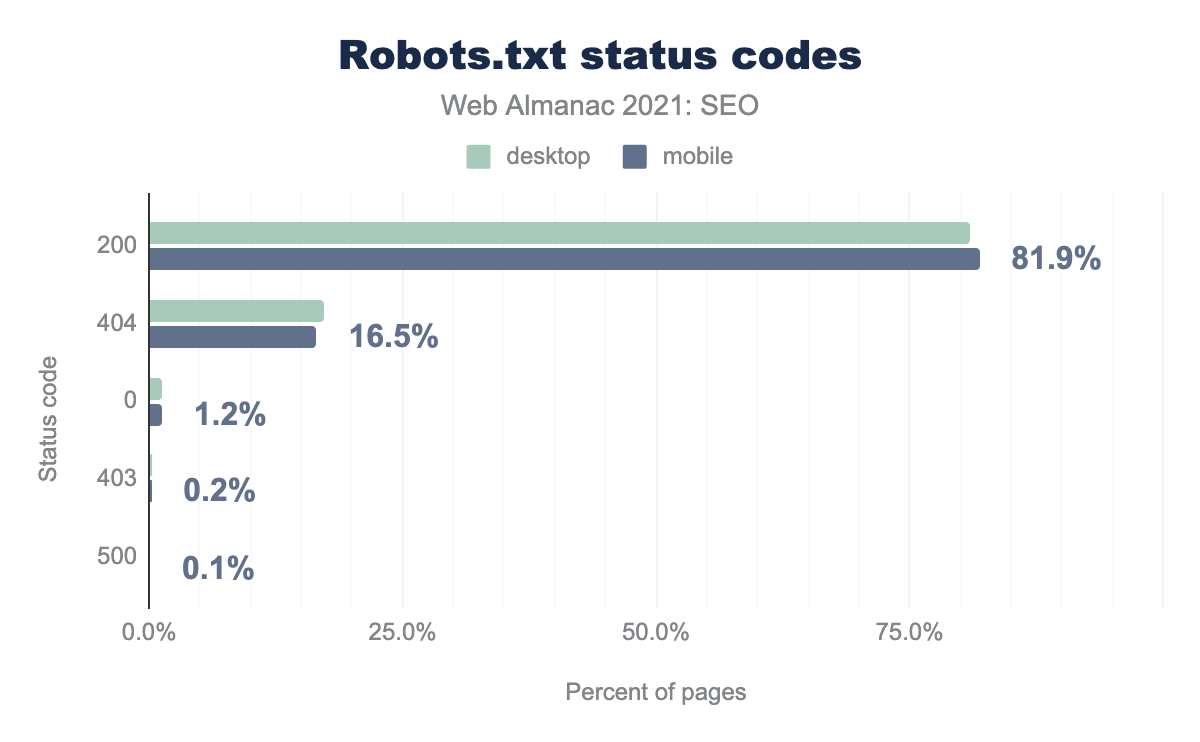
robots.txtを使用することで、ウェブサイトのオーナーは検索エンジンのロボットを制御できます。しかし、16.5%ものウェブサイトがrobots.txtファイルを持っていないというデータも出ています。
ウェブサイトが robots.txt ファイルを誤って設定している可能性があります。たとえば、人気のあるウェブサイトの中には、(おそらく間違って)検索エンジンをブロックしているものがありました。Googleはこれらのウェブサイトのインデックスを一定期間維持するかもしれませんが、最終的には検索結果での可視性は低下します。
robots.txtに関連するエラーのもう1つのカテゴリーは、アクセシビリティやネットワークエラーです。つまり、robots.txtは存在するがアクセスできない状態です。Googleが robots.txt ファイルを要求してこのようなエラーが発生した場合、ボットはしばらくの間、ページの要求を停止することがあります。これは、検索エンジンがあるページをクロールできるかできないか分からないので、robots.txtがアクセスできるようになるまで待つというロジックです。
データセットに含まれるウェブサイトの~0.3%が403 Forbiddenまたは5xxを返しました。ボットによってこれらのエラーの扱いが、異なる可能性があるため、Googlebotが何を見たのかは正確にはわかりません。
Googleが公開している2019年からの最新情報では、5%ものウェブサイトがrobots.txtで一時的に5xxを返し、26%ものウェブサイトが到達不能になっていたそうです。
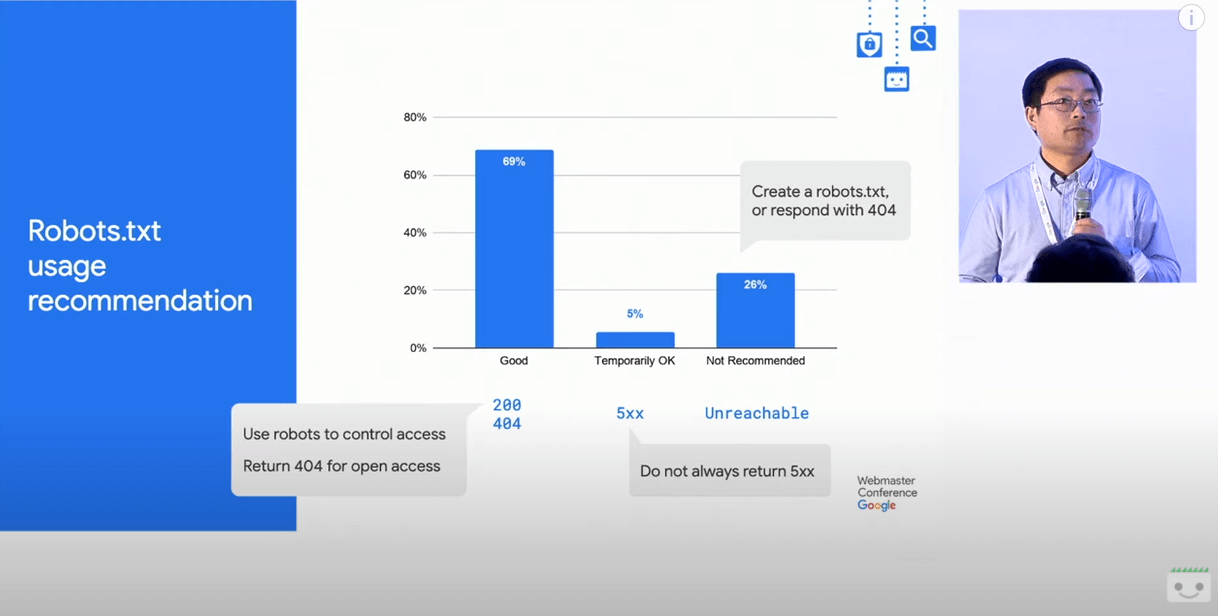
robots.txtで5xxを返すTemporarily OKでした。26%ものサイトがUnreachableでした。HTTP ArchiveとGoogleのデータの不一致の原因として、2つのことが考えられます。
Googleは2年前のデータを提示し、HTTP Archiveは最近の情報に基づいている、あるいは
HTTP Archiveは、CrUXのデータに含まれるほど人気のあるWebサイトに焦点を当て、Googleは既知のWebサイトをすべて訪問しようとします。
robots.txt のサイズ
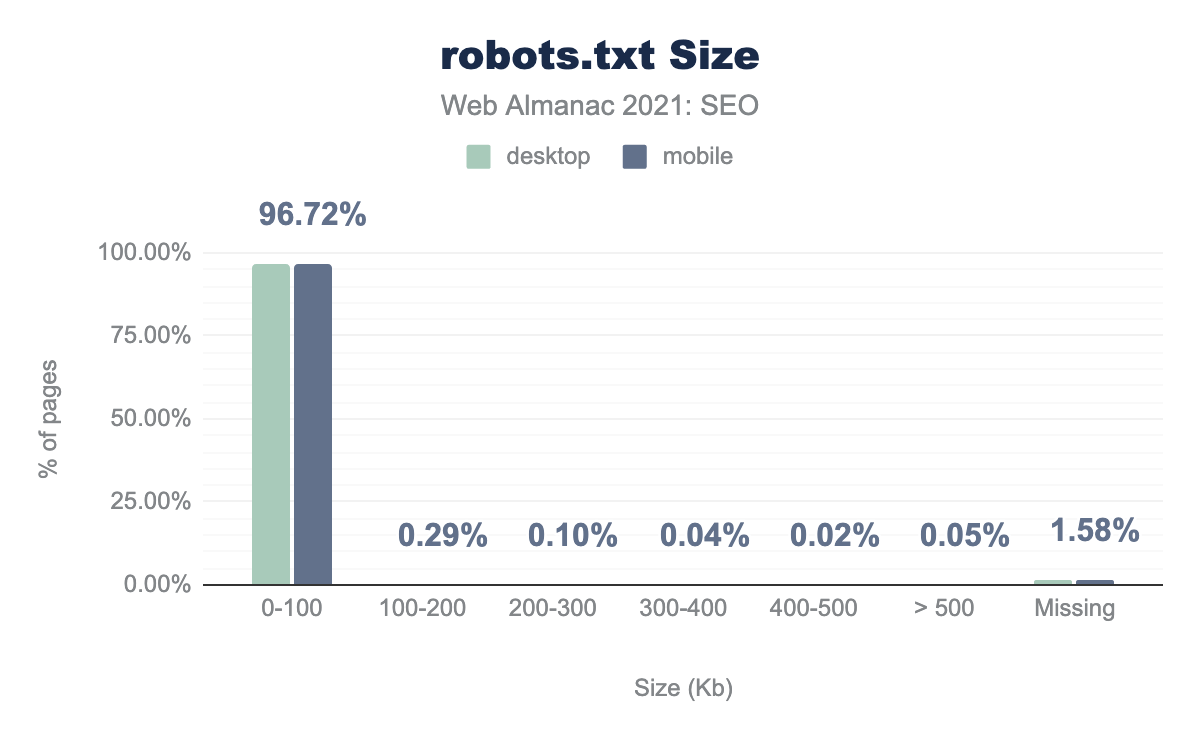
robots.txt のサイズ分布。
ほとんどのrobots.txtファイルは0~100kbの間でかなり小さいです。しかし、Googleの最大制限を超える500キロバイトを超えるrobots.txtファイルを持っている3,000以上のドメインを発見しました。このサイズ制限を超えたルールは無視されます。
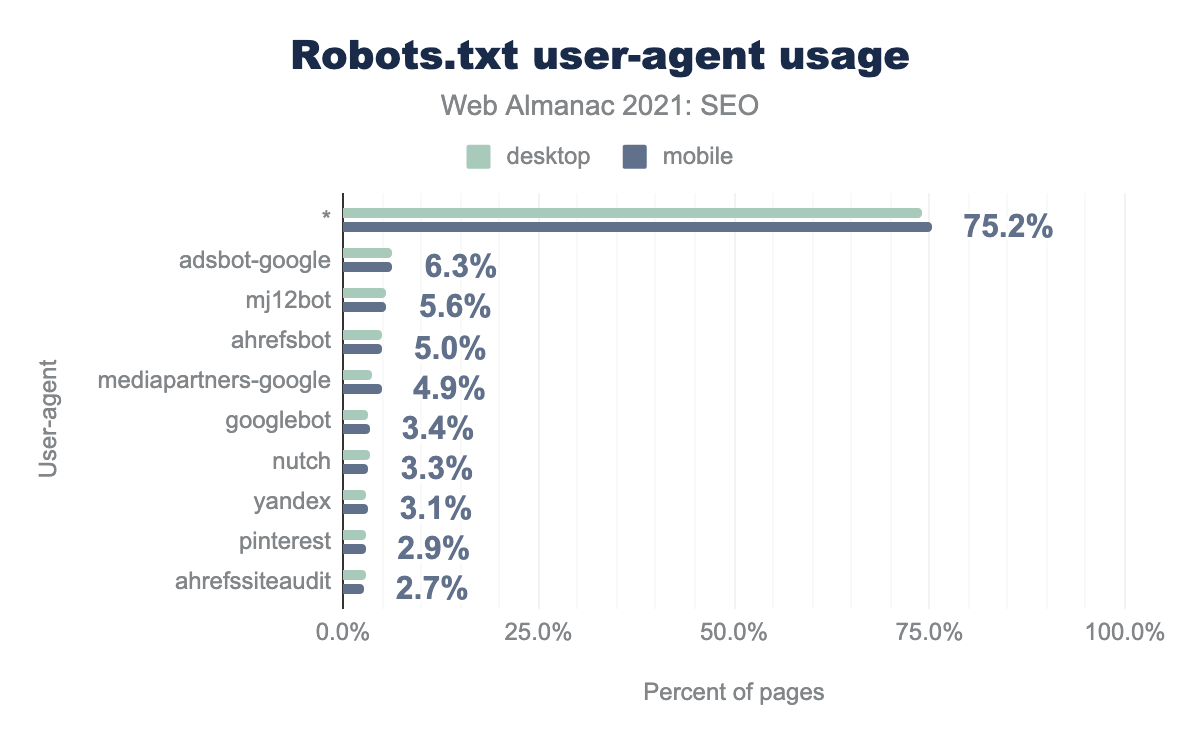
adsbot-google 6.3%、mj12bot 5.6%、ahrefsbot 5.0%、mediapartners-google 4.9%、googlebot 3.4%、nutch 3.3%、yandex 3.1%、pinterest 2.9%、ahrefssiteaudit 2.7%であることがわかりました。robots.txt のユーザーエージェント使用状況。
全ロボットに対するルールを宣言することも、特定のロボットに対するルールを指定することも可能です。ボットは通常、ユーザーエージェントのもっとも具体的なルールに従おうとします。User-agent: Googlebot はGooglebotのみを参照し、User-agent: *はより具体的なルールを持たないすべてのボットを指します。
もっとも指定されたユーザーエージェントのトップ5に、mj12bot (Majestic) と ahrefsbot (Ahrefs) というSEO関連の2つの人気ロボットが、あることがわかりました。
robots.txt 検索エンジンの内訳
| ユーザーエージェント | デスクトップ | モバイル |
|---|---|---|
| Googlebot | 3.3% | 3.4% |
| Bingbot | 2.5% | 3.4% |
| Baiduspider | 1.9% | 1.9% |
| Yandexbot | 0.5% | 0.5% |
robots.txt 検索エンジンの内訳。
特定の検索エンジンに適用されるルールを見ると、Googlebotがもっとも参照され、クロールされたWebサイトの3.3%に出現しています。
Bing、Baidu、Yandexなど他の検索エンジンに関連するロボットルールはあまり人気がない(それぞれ2.5%、1.9%、0.5%)。これらのボットにどのようなルールが適用されているかは調べていません。
Canonicalタグ
ウェブは膨大なドキュメントの集合体であり、その中には重複しているものもあります。重複コンテンツの問題を防ぐために、ウェブマスターはcanonicalタグを使って、どのバージョンをインデックスされるのが好ましいかを検索エンジンに伝えることができます。また、canonicalは、ランキングページへのリンクなどのシグナルを統合するのに役立ちます。
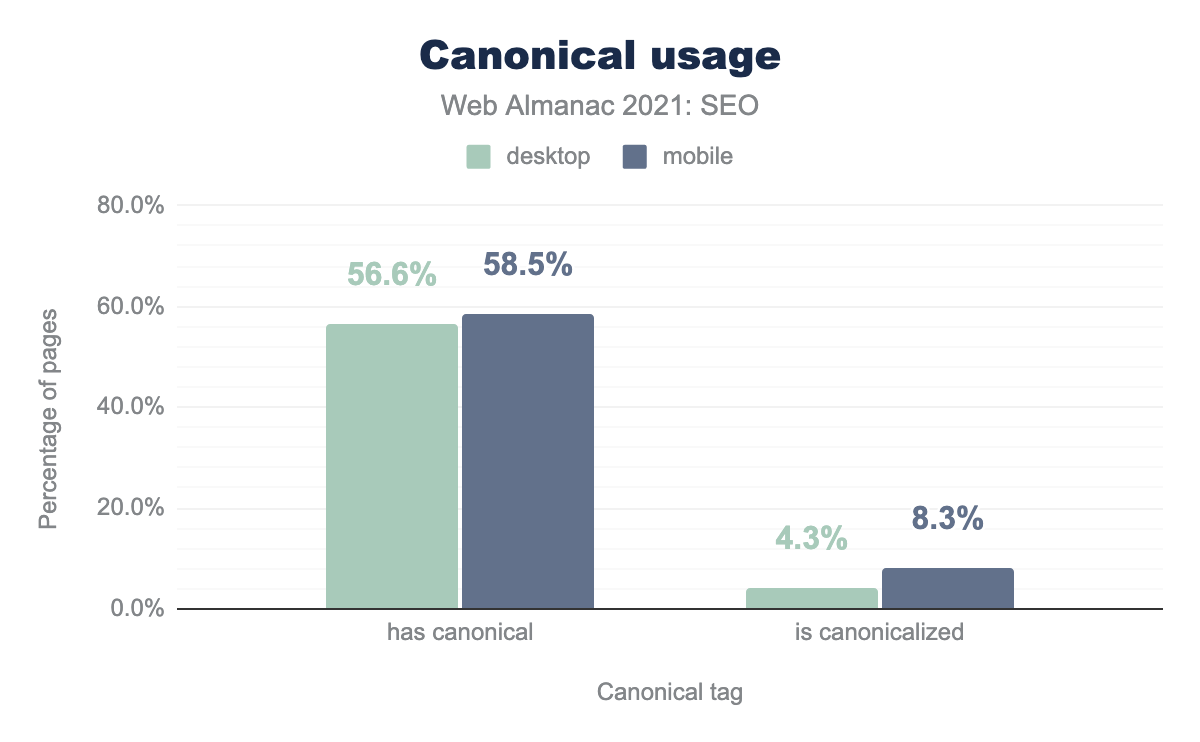
このデータでは、年々canonicalタグの導入が進んでいることがわかります。たとえば、2019年版では、48.3%のモバイルページがcanonicalタグを使用していたことがわかります。2020年版では53.6%に増え、2021年版では58.5%となっています。
モバイルページにはデスクトップページよりも多くのcanonicalが設定されています。また、モバイルページの8.3%、デスクトップページの4.3%が別のページに正規化されており、Googleやその他の検索エンジンにcanonicalタグで示されたページがインデックスされるべきページであることを明確に示唆するようになっています。
モバイルで正規化されたページの数が多いのは、個別のモバイルURLを使用しているWebサイトに関連していると思われます。このような場合、Googleは対応するデスクトップのURLを指すrel="canonical"タグを設置することを推奨しています。
今回のデータセットと分析は、ウェブサイトのホームページに限定したものであり、テスト対象ウェブサイトのすべてのURLを考慮すると、データは異なる可能性があります。
canonicalタグを実装する2つの方法
canonicalを実装する場合、指定する方法は2つあります。
- ページのHTMLの
<head>セクションで - HTTPヘッダーの中で(
LinkHTTPヘッダーを経由して)
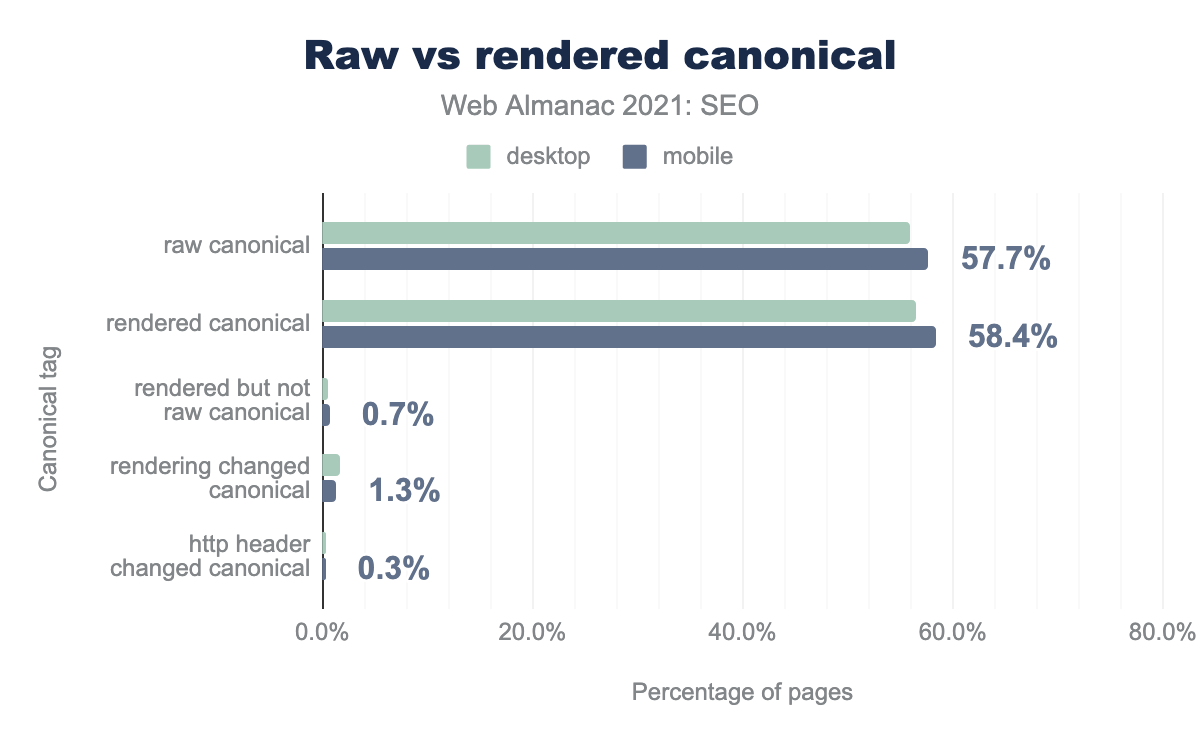
canonicalタグをHTMLページの<head>に実装することは、Linkヘッダーを使う方法よりもはるかに一般的です。一般に、headセクションにタグを実装する方が簡単だと考えられており、そのため、使用率が非常に高くなっています。
また、配信された未加工のHTMLと、JavaScriptを適用した後のレンダリングHTMLの間で、canonicalにわずかな変化(1%未満)が見られました。
canonicalタグの矛盾
ページには、複数のcanonicalタグを含むことがあります。このように相反するシグナルがある場合、検索エンジンはそれを把握しなければなりません。GoogleのSearch Advocateの一人であるMartin Splittは、かつてGoogle側で未定義の動作を引き起こすと発言しています。
先ほどの図では、1.3%ものモバイルページが、最初のHTMLとレンダリングバージョンで異なるcanonicalタグを持っていることが示されています。
昨年の章では次のように指摘しています “実装方法の違いでも同様の衝突が見られ、モバイルページの0.15%、デスクトップページの0.17%が、HTTPヘッダーとHTMLヘッドを介して実装したcanonicalタグの衝突を示しました”。
その衝突に関する今年のデータは、さらに心配なものです。デスクトップで0.4%、モバイルでは0.3%のケースでページが矛盾する信号を送っています。
Web Almanacのデータはホームページのみを対象としているため、アーキテクチャの奥深くに位置するページにはさらに問題のある可能性があり、これらは正規化シグナルを必要なページである可能性が高くなります。
ページ経験
2021年は、ユーザー体験への注目が高まりました。Googleはページ体験の更新を開始し、HTTPSやモバイルフレンドリーなどの既存のシグナルと、Core Web Vitalsという新しいスピード指標を盛り込みました。
HTTPS
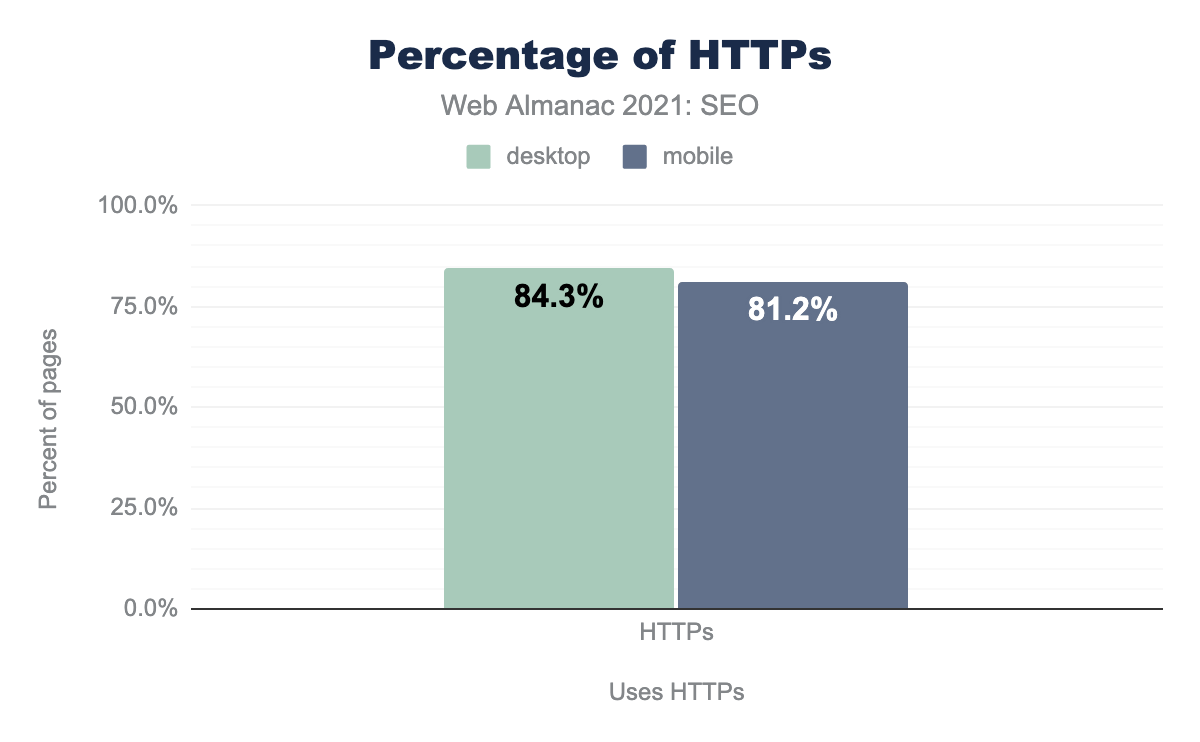
HTTPSの採用は依然として増加している。モバイルページの81.2%、デスクトップページの84.3%でHTTPSがデフォルトとして採用されました。これは、前年比でモバイルサイトでは約8%、デスクトップサイトでは7%増加しています。
モバイルフレンドリー
今年はモバイルの利便性が若干向上しています。レスポンシブデザインの導入は増加し、ダイナミックサーブは比較的横ばいで推移しています。
レスポンシブデザインは同じコードを送信し、画面サイズに応じてウェブサイトの表示方法を調整するのに対し、ダイナミックサービングはデバイスに応じて異なるコードを送信します。レスポンシブWebサイトの識別にはviewportメタタグが、Vary: User-Agent headerは、ダイナミックサービングを使用しているウェブサイトを識別するために使用されます。
viewport メタタグを使用したモバイルページの割合。
モバイルページの91.1%がviewportメタタグを含んでおり、2020年の89.2%から増加した。また、デスクトップページの86.4%がviewport metaタグを含んでおり、2020年の83.8%から増加しています。
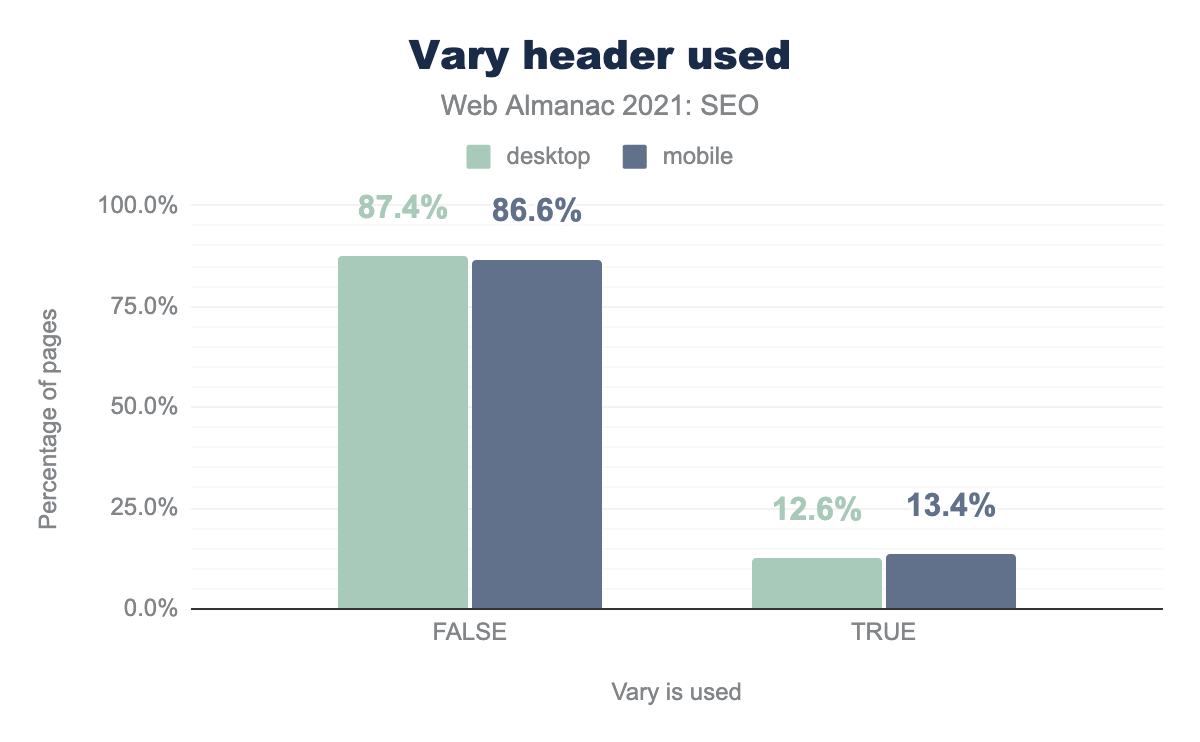
vary ヘッダーを示す棒グラフ。ほとんどのウェブページがレスポンスデザインを利用していること(デスクトップ:87.4%、モバイル:86.6%)と、ダイナミックサーブを利用しているページ(デスクトップ:12.6%、モバイル:13.4%)を比較すると、レスポンスデザインの方が多いようです。Vary: User-Agent ヘッダーの使用状況。
また、Vary: User-Agentヘッダーについては、このフットプリントのデスクトップページの12.6%、モバイルページの13.4%がこのヘッダーを使用しており、数値はほとんど変わりません。
モバイルフレンドリーに失敗した最大の理由のひとつは、13.5%のページが読みやすいフォントサイズを使用していないことでした。つまり、60%以上のテキストが、モバイルで読みにくい12pxより小さいフォントサイズだったということです。
Core Web Vitals
Core Web Vitalsは、Googleのページ体験シグナルの一部である新しい速度指標です。この指標は、最大コンテンツペイント(LCP)による視覚的負荷、累積レイアウトシフト(CLS)による視覚的安定性、最初の入力遅延(FID)を使用した対話性を測定します。
このデータは、オプトインしたChromeユーザーの実測データを記録した「Chromeユーザーエクスペリエンスレポート(CrUX)」から得られたものです。
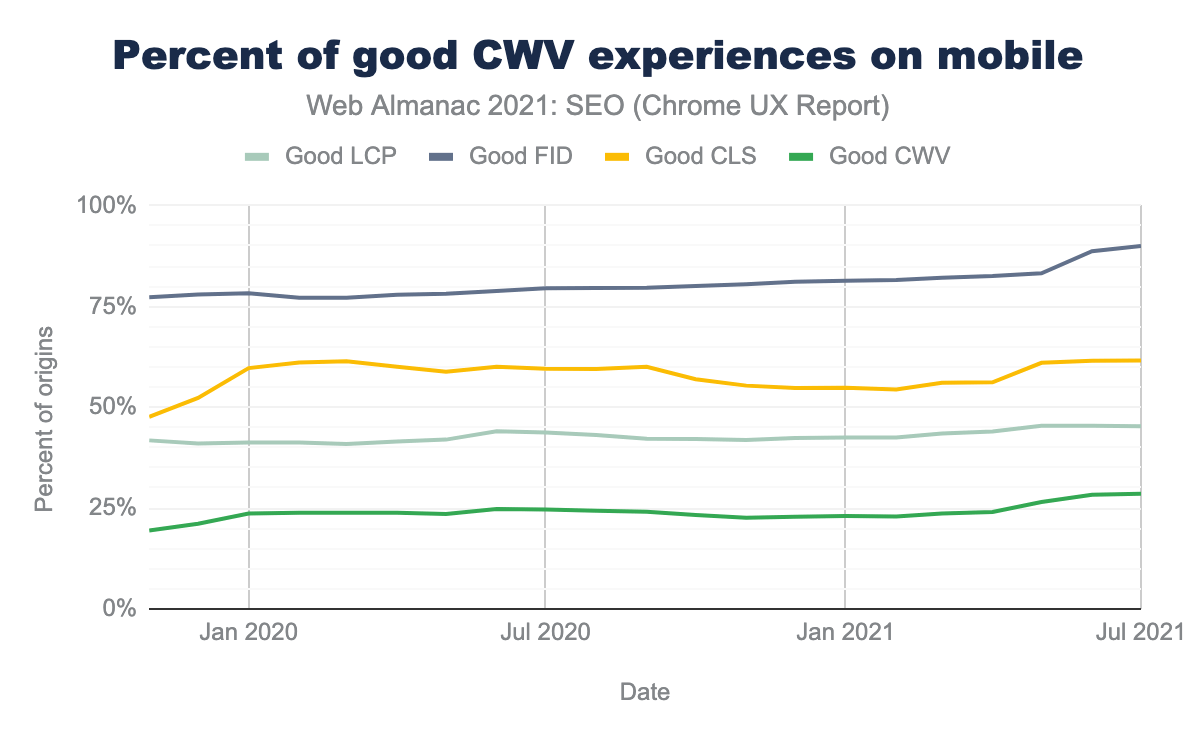
モバイルサイトの29%がコアウェブバイタルの基準値をクリアしており、昨年の20%から増加しています。ほとんどのWebサイトがFIDをクリアしていますが、WebサイトのオーナーはCLSとLCPの改善に苦戦しているようです。このトピックについては、パフォーマンスの章を参照してください。
On-Page
検索エンジンは、あなたのページのコンテンツを見て、それが検索クエリに関連する結果であるかどうかを判断します。その他のページ上の要素も、検索エンジンでの順位や見た目に影響を与える場合があります。
メタデータ
メタデータには、<title> 要素と <meta name="description"> タグが含まれます。メタデータは直接的、間接的にSEOのパフォーマンスに影響を与えることがあります。
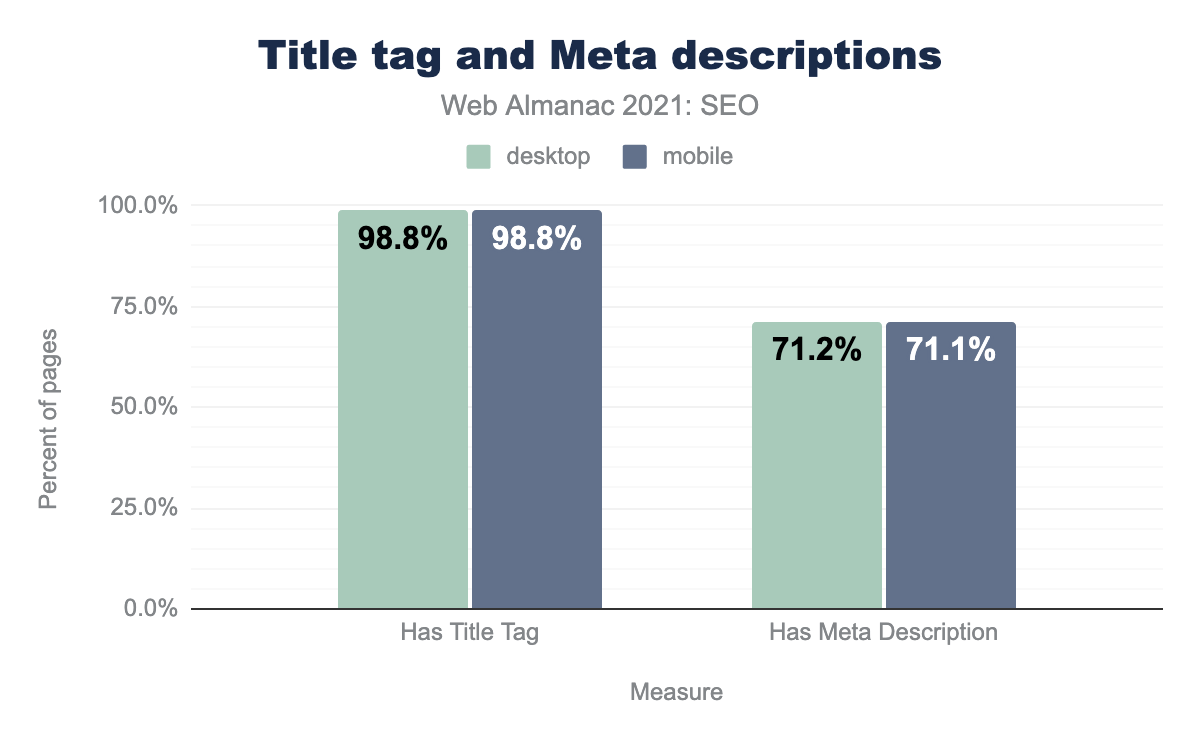
title要素があり、モバイルページとデスクトップページの71.1%にメタ記述がありました。2021年、デスクトップとモバイルのページの98.8%が <title> 要素を持っていた。デスクトップとモバイルのホームページの71.1%が <meta name="description"> タグを持っていました。
<title> 要素
<title>要素は、ページの関連性に関する強いヒントを提供するページ上のランキング要因であり、検索エンジンの結果ページ(SERP)に表示されることがあります。2021年8月、Googleは検索結果のタイトルをより多く書き換えるようになりました。
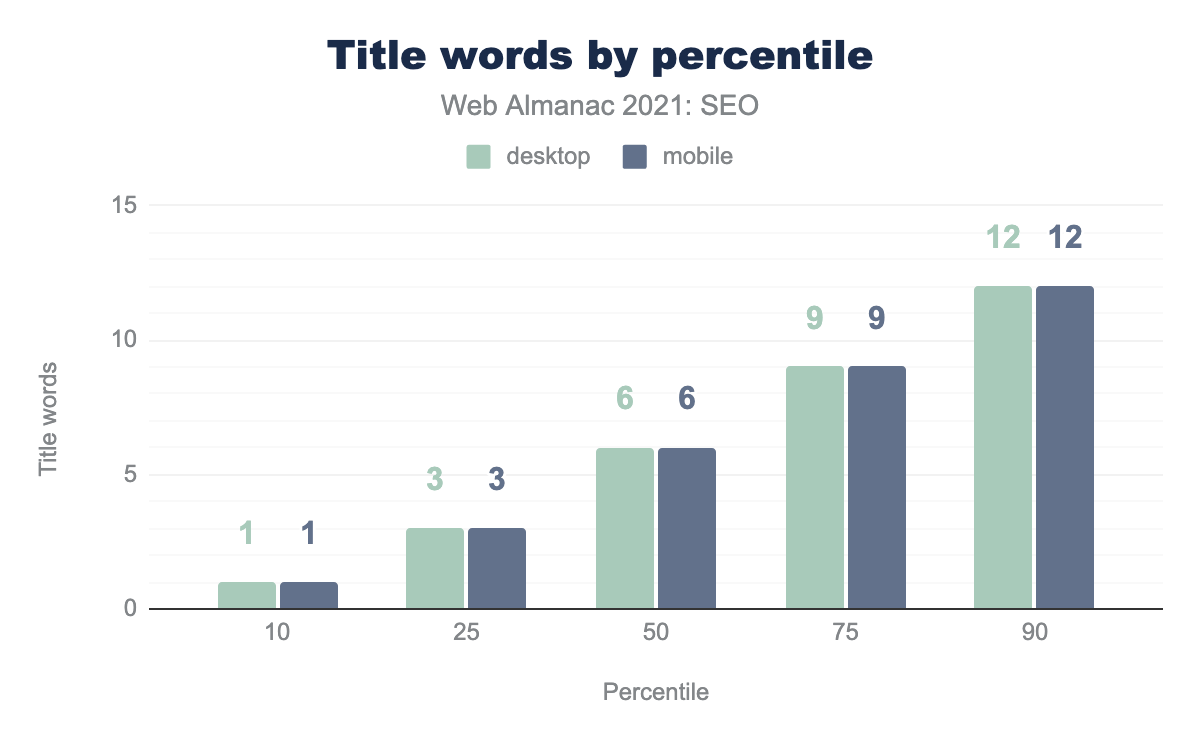
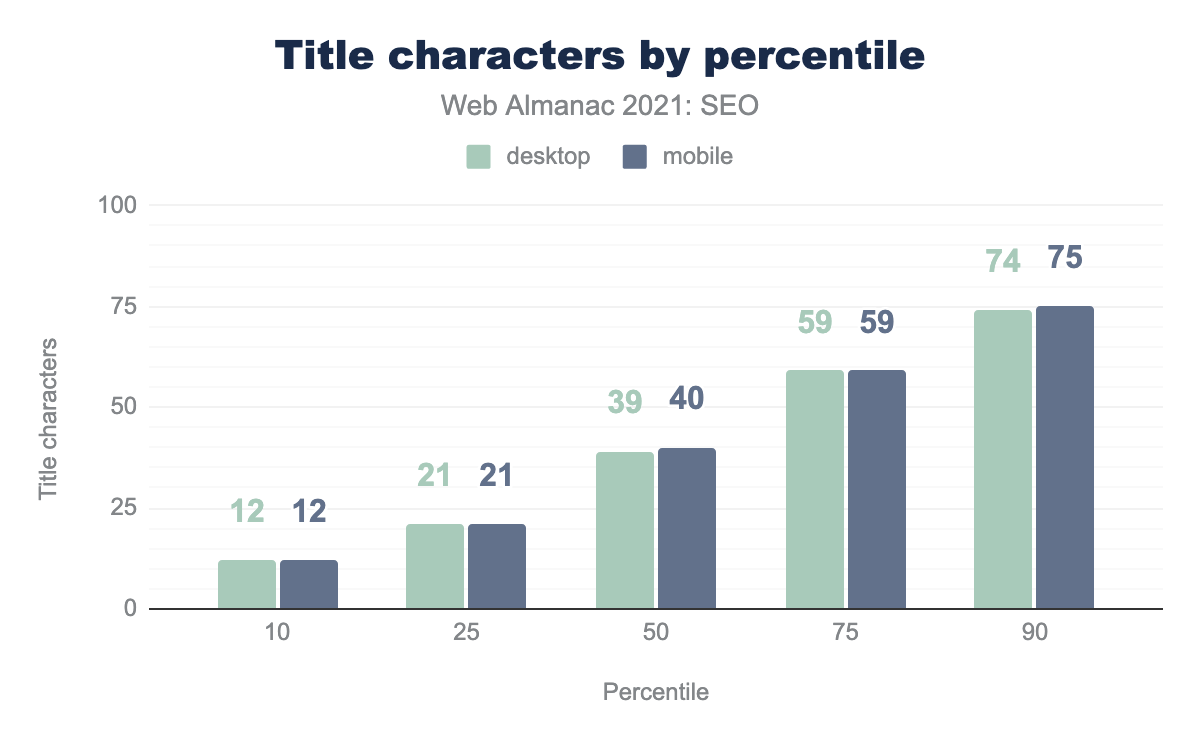
2021年に
- 中央のページ
<title>には6つの単語が含まれていた。 - ページの
<title>の中央値は、デスクトップとモバイルでそれぞれ39文字と40文字でした。 - 10%のページで、12語を含む
<title>要素があった。 - デスクトップとモバイルのページの10%に、それぞれ74文字と75文字を含む
<title>要素がありました。
これらの統計のほとんどは、昨年から比較的変化していません。これらはホームページのタイトルで、より深いページで使用されるものより短い傾向があることに注意してください。
メタ記述タグ
<meta name="description> タグは、ランキングに直接影響を与えません。しかし、SERP上でページの説明文として表示されることがあります。
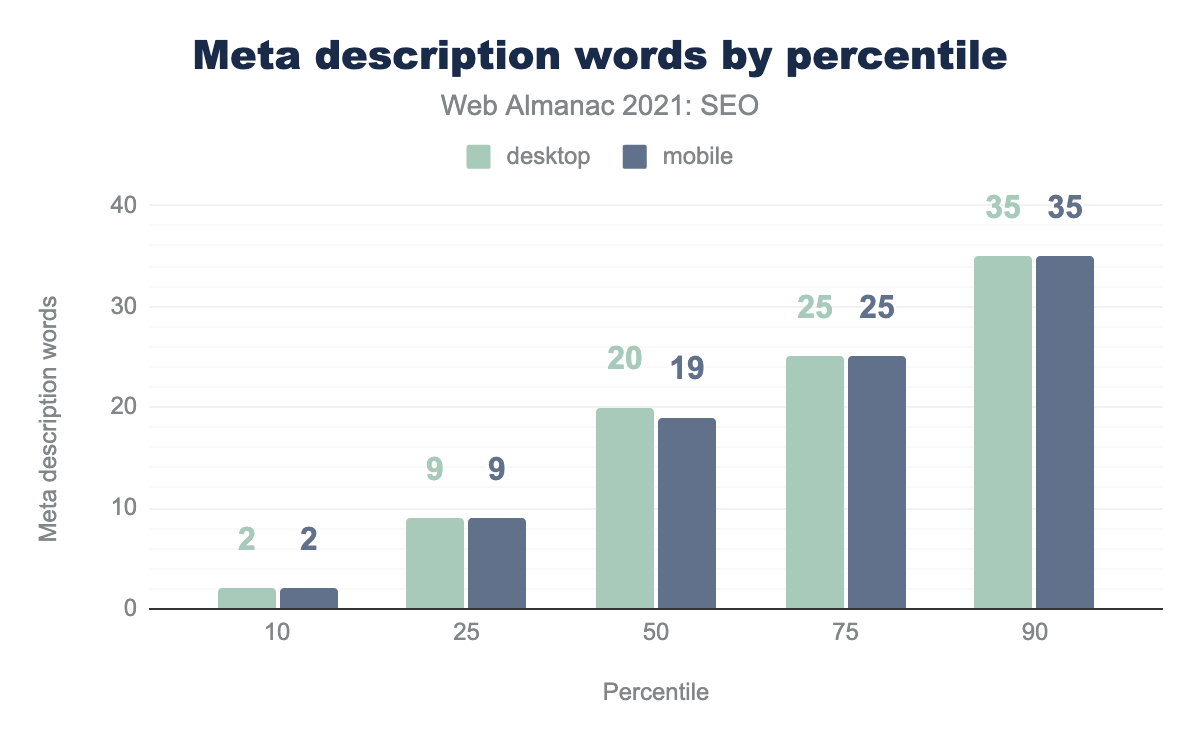
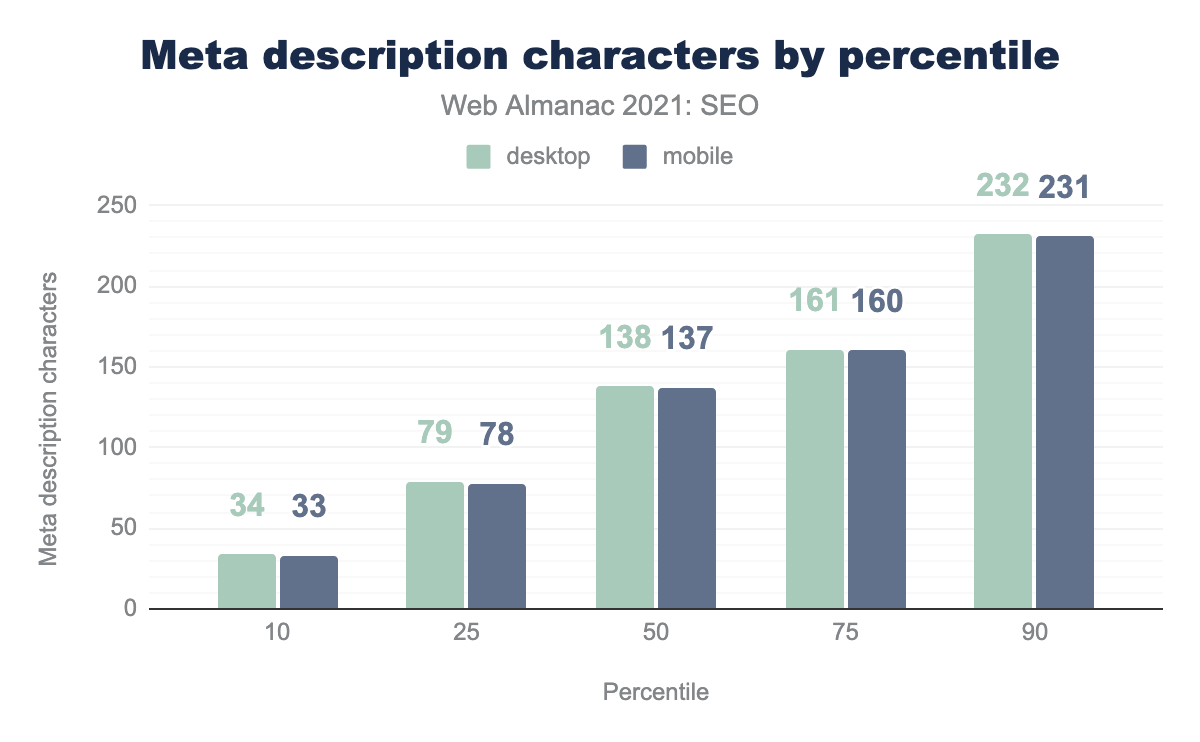
2021年に
- デスクトップとモバイルのページの
<meta name="description>タグには、それぞれ20語と19語が含まれています(中央値)。 - デスクトップとモバイルページの
<meta name="description>タグ文字数の中央値は、それぞれ138文字と127文字でした。 - デスクトップとモバイルのページの10%に、35語を含む
<meta name="description>タグがありました。 - デスクトップとモバイルのページの10%に、それぞれ232文字と231文字を含む
<meta name="description>タグがありました。
この数値は、昨年と比較すると、ほぼ横ばいです。
画像
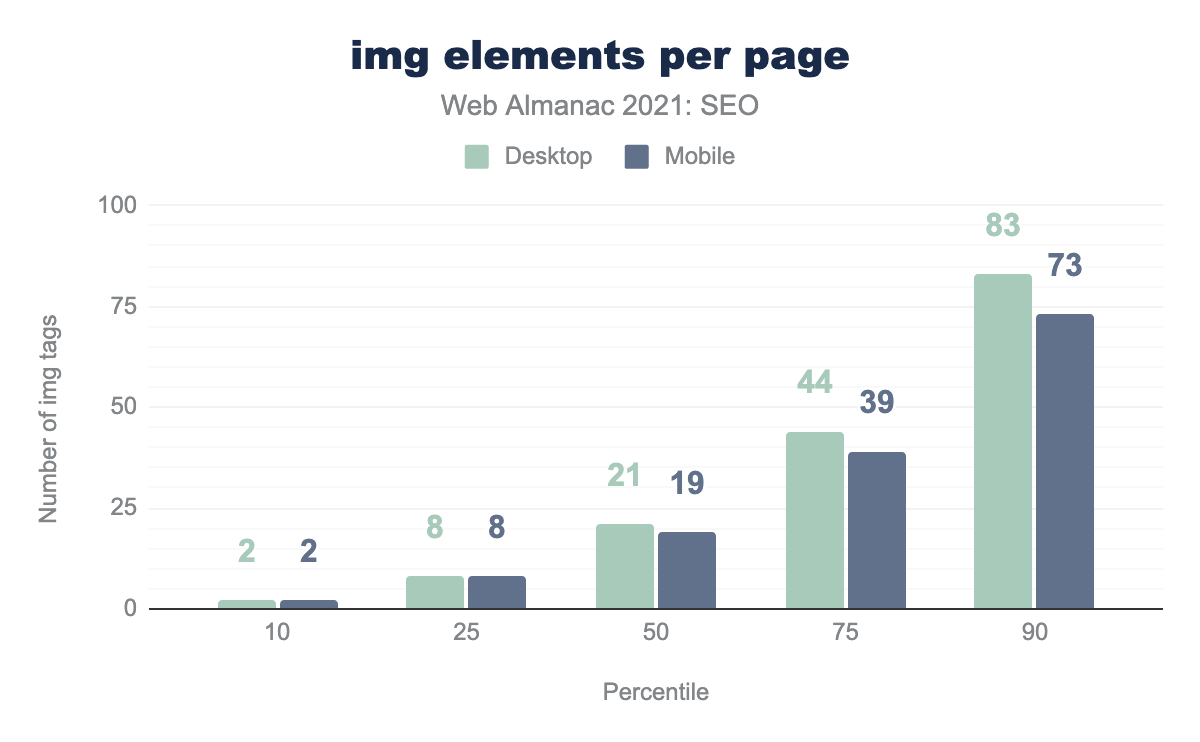
<img>要素の数を示す棒グラフです。デスクトップ用ページの中央値は21個の <img> 要素、モバイル用ページの中央値は19個の <img> 要素を備えていました。画像は、画像検索順位やページパフォーマンスに影響を与えるため、直接的・間接的にSEOに影響を与える可能性があります。
- 10%のページでは、
<img>タグが2つ以下になっています。これは、デスクトップとモバイルの両方に当てはまります。 - デスクトップ用ページの中央値には21個の
<img>タグがあり、モバイル用ページの中央値には19個の<img>タグがあります。 - デスクトップページの10%は、83個以上の
<img>タグを持っています。モバイルページの10%は、73個以上の<img>タグを持っています。
この数字は2020年以降、ほとんど変化していません。
画像の alt 属性
<img> 要素の alt 属性は、画像の内容を説明するのに役立ち、アクセシビリティへ影響を及ぼします。
なお、alt属性の欠落は問題を示さない場合があります。ページには極端に小さい画像や空白の画像が含まれていることがありますが、SEO(あるいはアクセシビリティ)上の理由から alt 属性は必要でありません。
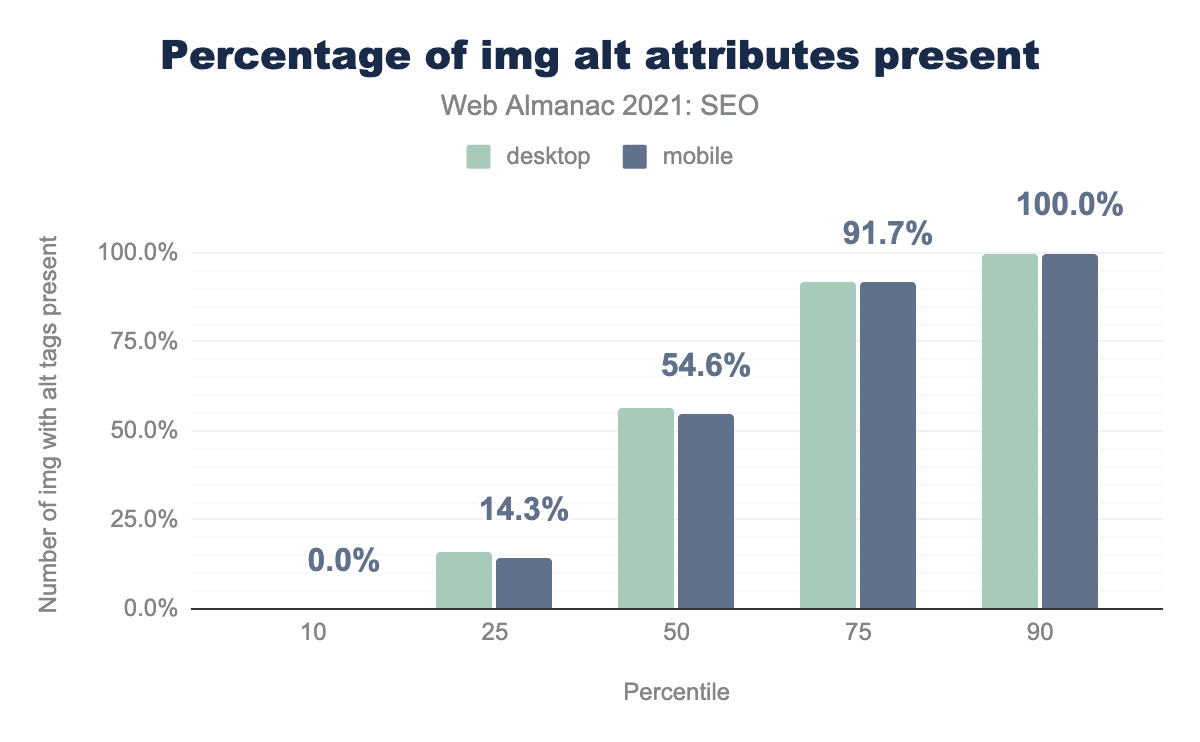
alt属性が存在する画像の数を示す棒グラフです。このデータから、中央のウェブページには、モバイルページで54.6%、デスクトップページでは56.5%のalt属性の付いた画像が含まれていることがわかりました。alt 属性を含む画像の割合。
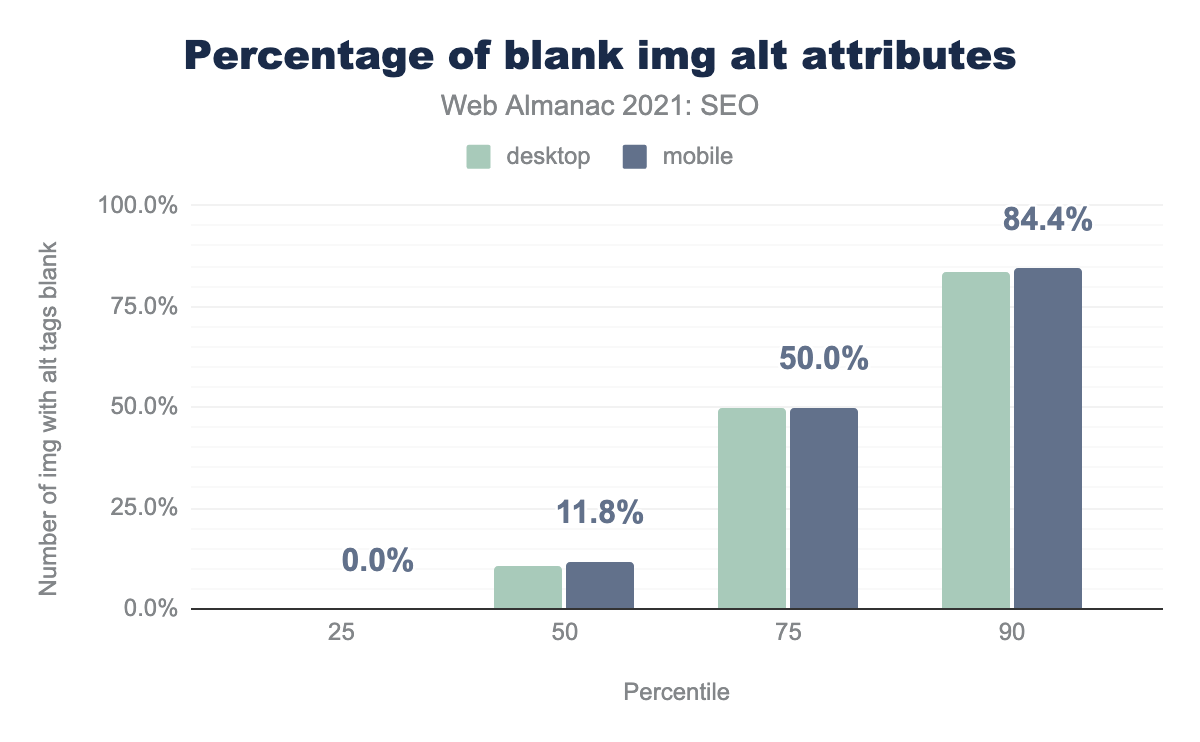
alt属性がフィーチャーされる割合を示す棒グラフ。中央のウェブページでは、デスクトップで10.5%、モバイルでは11.8%の空白のalt属性が表示されています。alt 属性が空白の割合。
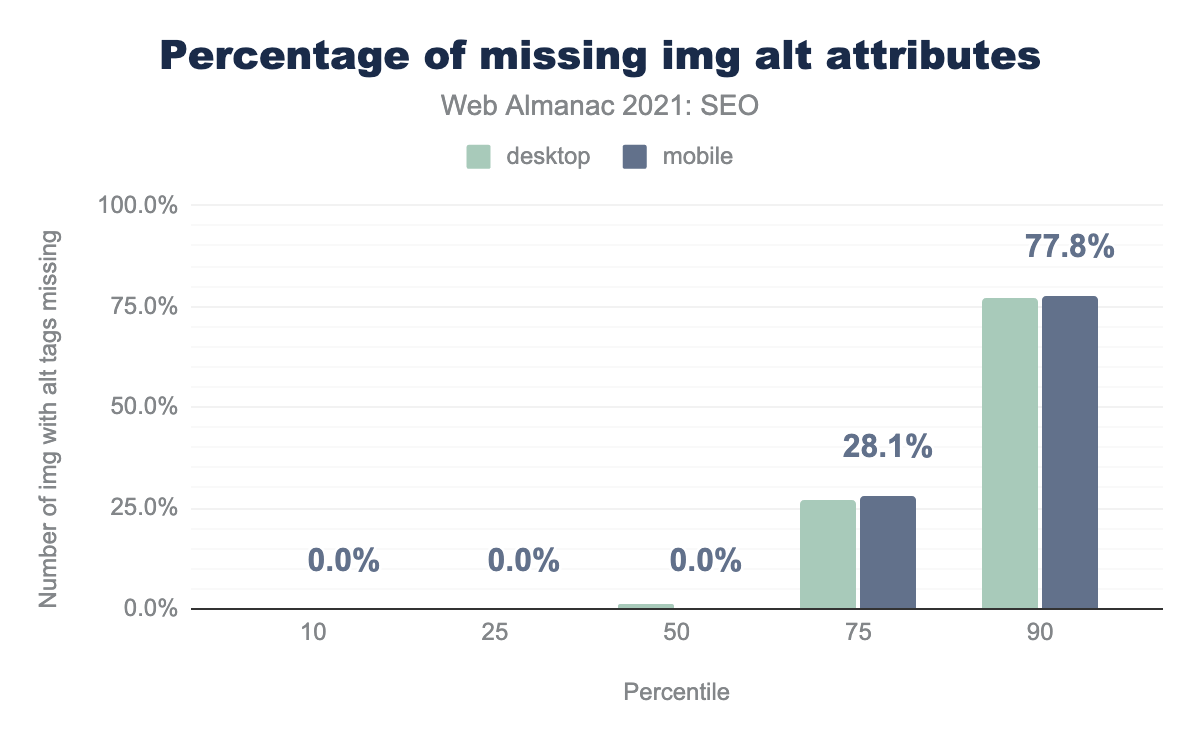
alt属性が欠落している画像の割合を示す棒グラフです。中央のウェブページでは、デスクトップでは alt 属性の欠落が1.4%、モバイルでは alt 属性の欠落が0%でした。alt属性がない画像の割合。
私たちはそれがわかりました
- デスクトップ用ページの中央値では、56.5%の
<img>タグにalt属性が設定されています。これは、2020年に比べてわずかに増加しています。 - モバイルページの中央値では、54.6%の
<img>タグにalt属性が設定されています。これは、2020年と比較して若干の増加です。 - しかし、デスクトップとモバイルページの中央値では、10.5%と11.8%の
<img>タグがalt属性を空白にしています(それぞれ)。これは事実上、2020年と同じです。 - 中央のデスクトップとモバイルのページでは、
<img>タグにalt属性なしがゼロか、それと近い値になっています。これは、中央ページにある<img>タグの2~3%にalt属性がなかった2020年に比べて改善されています。
画像 loading 属性
<img> 要素の loading 属性は、ユーザーエージェントがページ上の画像のレンダリングと表示をどのように優先させるかに影響します。ユーザー体験やページの読み込み性能に影響を与える可能性があり、これらはいずれもSEOの成功に影響を与えます。
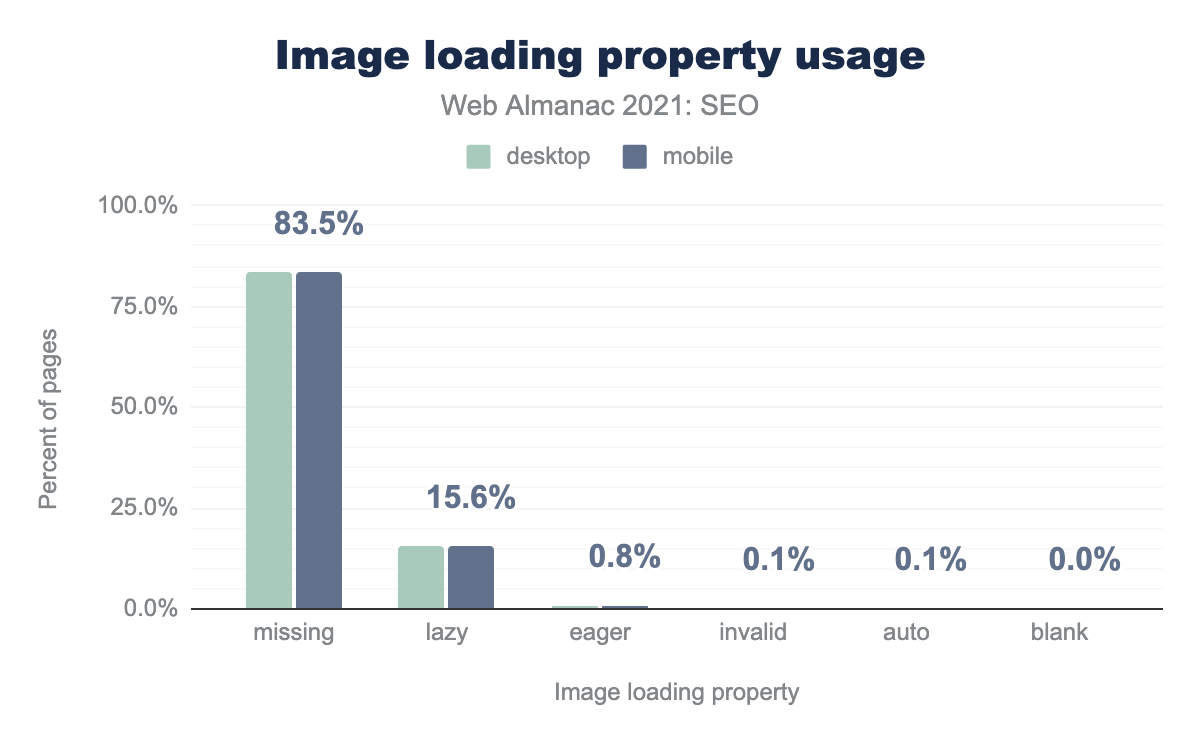
loading="lazy" を使用しており、loading="eager" はデスクトップとモバイルのページの0.8%に過ぎないことがわかりました。その他のケースは、デスクトップとモバイルのページで1%未満です。これには、無効なプロパティや空白のプロパティ、または loading="auto" を持つケースが含まれます。私たちはそれを見たのです。
- 85.5%のページでは、画像の
loadingプロパティが使用されていません。 - 15.6%のページが
loading="lazy"を使用しており、ビューポートに入る寸前まで画像の読み込みを遅らせています。 - 0.8%のページでは、ブラウザがコードを読み込むと同時に画像を読み込む
loading="eager"が使用されています。 - 0.1%のページで無効なローディングプロパティが使用されています。
- 0.1%のページでは、ブラウザのデフォルトの読み込み方法を使用する
loading="auto"が使用されています。
単語数
ページ内の文字数はランキング要因ではありませんが、ページが文字を配信する方法はランキングに大きな影響を与えます。言葉は、未加工のページコードに含まれることも、レンダリングされたコンテンツに含まれることもあります。
レンダリング文字数
まず、レンダリングされたページの内容を見ます。レンダリングとは、ブラウザがすべてのJavaScriptとDOMまたはCSSOMを変更する他のコードを実行した後のページのコンテンツです。
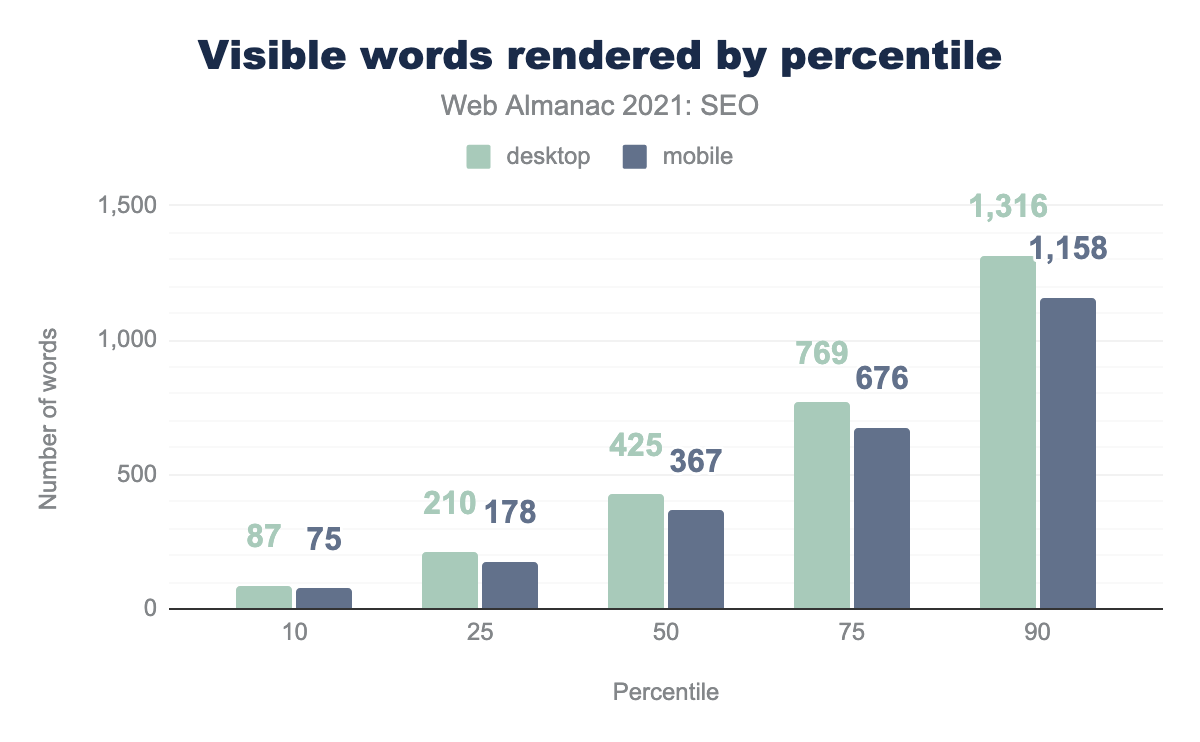
- デスクトップページのレンダリング文字数の中央値は425語で、2020年には402語になっています。
- モバイルページのレンダリングの中央値は367語であるのに対し、2020年には348語となっています。
- モバイルページのレンダリングは、デスクトップページのレンダリングより13.6%少ない単語数です。Googleはモバイル専用のインデックスであることに注意してください。モバイル版にないコンテンツはインデックスされない可能性があります。
未加工のワード数
次に、未加工のページコンテンツについて見ていきます。未加工とは、ブラウザがJavaScriptやDOMやCSSOMを修正する他のコードを実行する前のページのコンテンツのことです。ソースコードで配信され、目に見える「未加工」のコンテンツです。
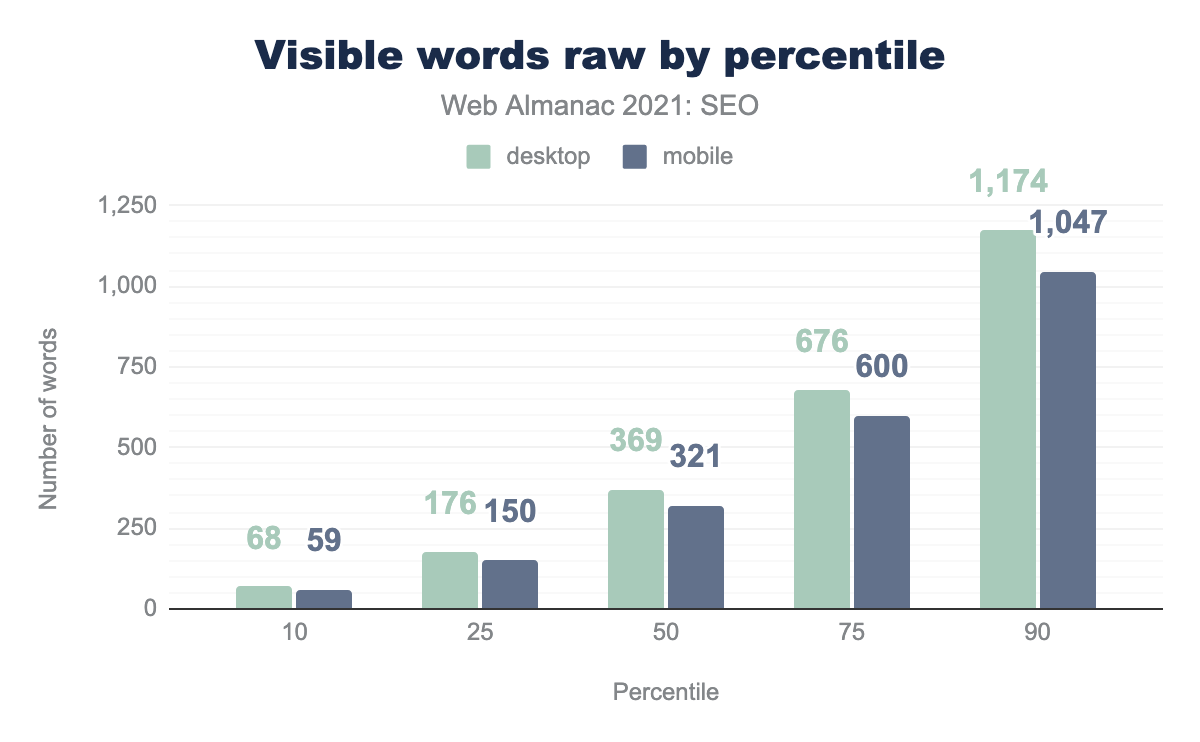
- デスクトップページの中央値は369語であるのに対し、2020年には360語になっています。
- モバイルページの中央値は321語であるのに対し、2020年には312語となっています。
- モバイルの未加工ページは、デスクトップの未加工ページよりも13.1%少ない単語しか含まれていません。Googleはモバイル専用のインデックスであることに注意してください。モバイルHTML版にないコンテンツは、インデックスされない可能性があります。
全体として、デスクトップ端末で書かれたコンテンツの15%が、モバイル版では14.3%がJavaScriptによって生成されています。
構造化データ
これまで検索エンジンは、非構造化データ、つまりページ上のテキストを構成する単語、段落、その他のコンテンツの山を扱ってきた。
スキーママークアップやその他の構造化データは、検索エンジンがコンテンツを解析し、整理するための別の方法を提供します。構造化データは、Googleの検索機能の多くに力を与えています。
構造化データは、ページ上の単語と同様に、JavaScriptで変更できます。
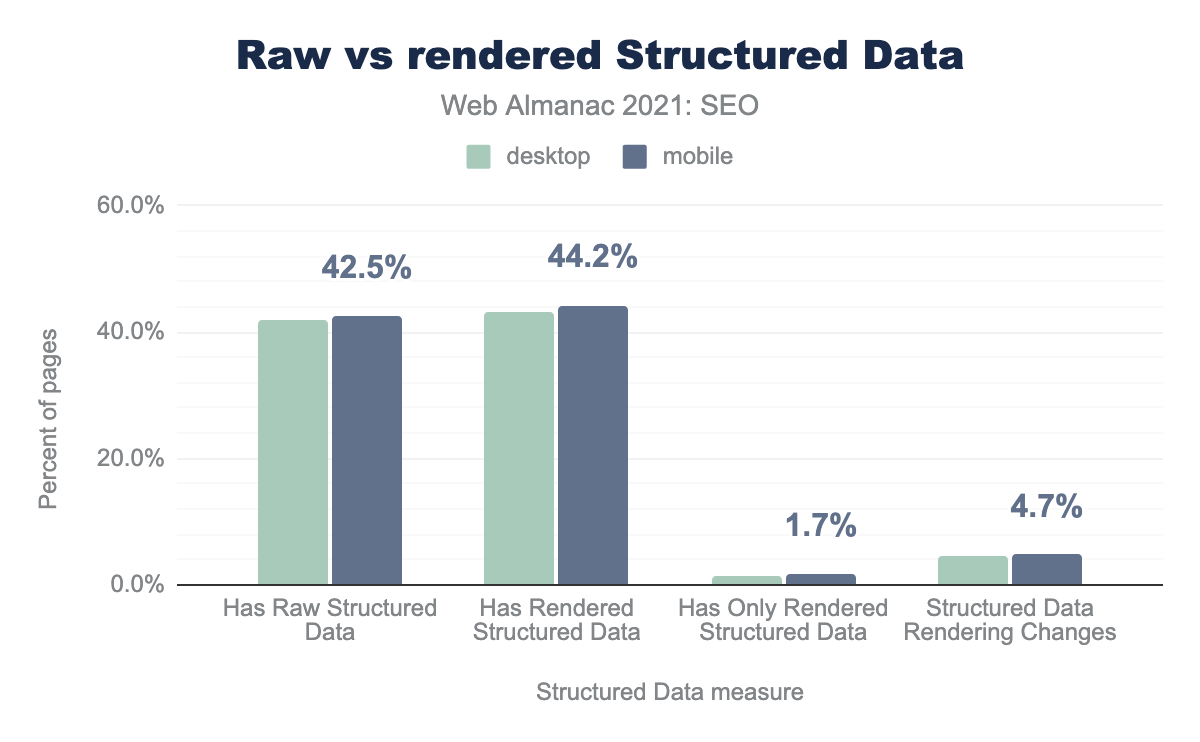
モバイルページの42.5%、デスクトップページの41.8%が、HTML内に構造化データを有しています。モバイルページの4.7%、デスクトップページの4.5%で、JavaScriptが構造化データを修正しています。
モバイルページの1.7%、デスクトップページの1.4%で、最初のHTMLレスポンスに存在しない構造化データがJavaScriptによって追加されています。
もっとも一般的な構造化データ形式
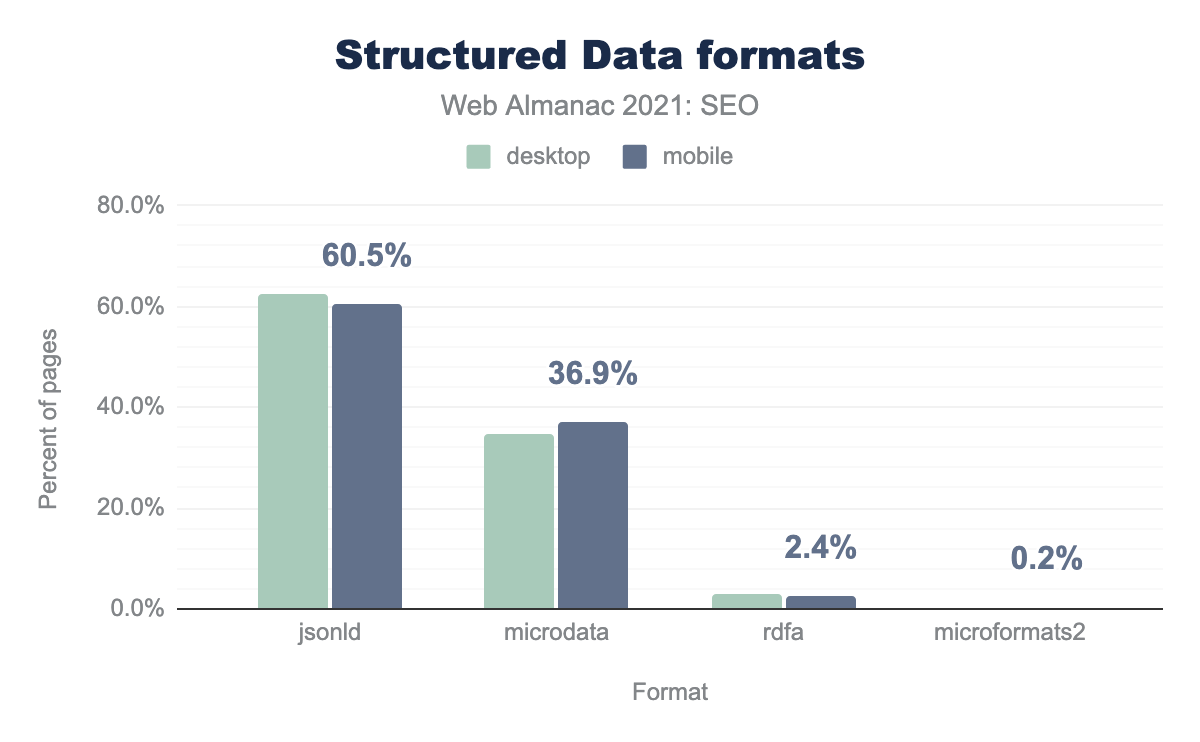
構造化データをページに含めるには、いくつかの方法があります。JSON-LD、microdata、RDFa、microformats2などです。JSON-LDは、もっとも一般的な実装方法です。構造化データを持つデスクトップとモバイルのページの60%以上が、JSON-LDで実装しています。
構造化データを実装しているWebサイトのうち、デスクトップおよびモバイルページの36%以上がmicrodataを使用しており、RDFaまたはmicroformats2を使用しているページは3%未満です。
構造化データの導入は昨年より少し増えている。2020年の30.6%に対し、2021年は33.2%のページで使用されています。
もっとも一般的なスキーマの種類
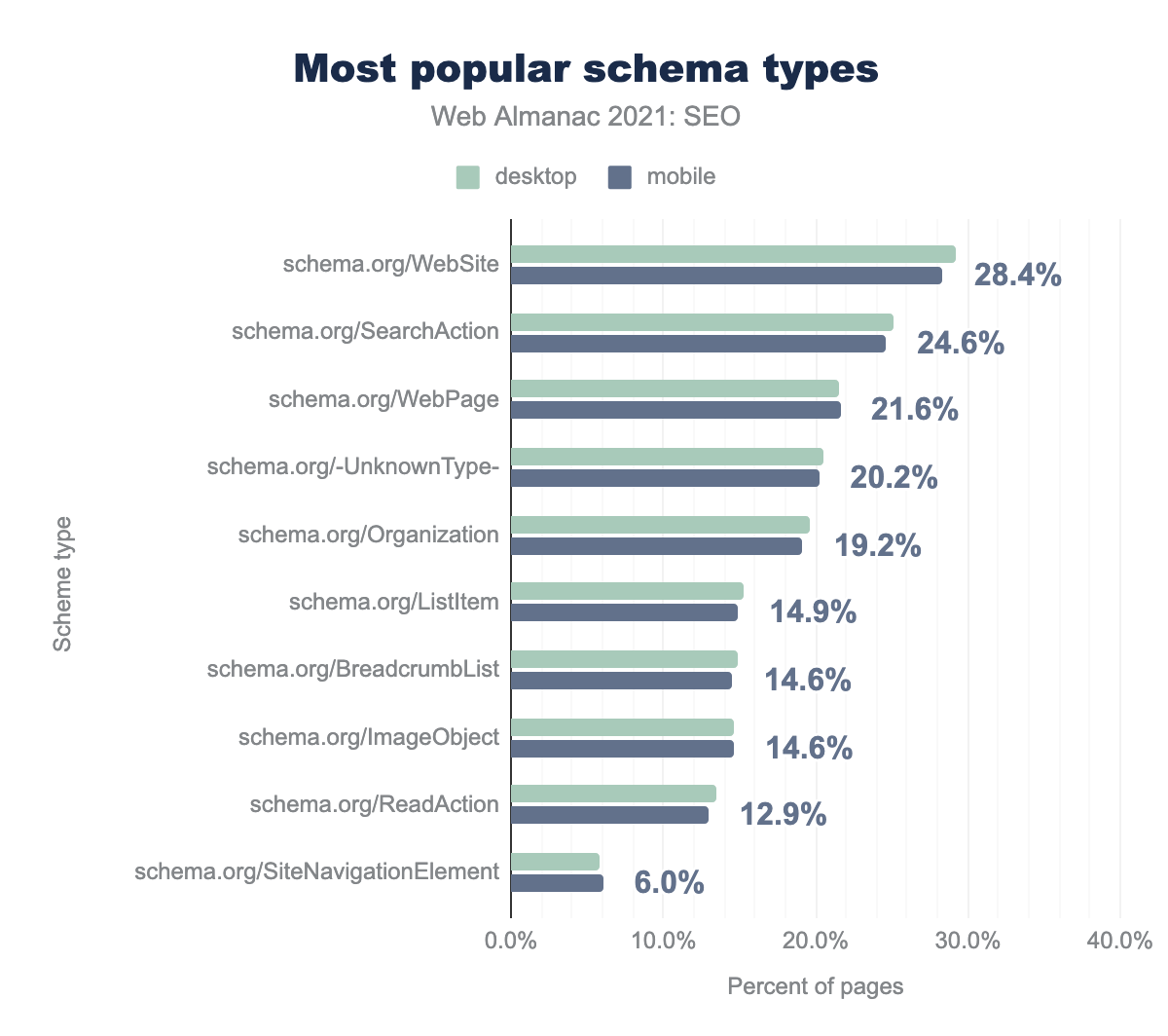
ホームページでもっともよく見られるスキーマタイプは WebSite、SearchAction、WebPage です。SearchAction は、サイトリンク検索ボックス を動かすもので、Googleが検索結果ページで表示することを選択できます。
<h> 要素(見出し)
見出し要素(<h1>、<h2>など)は、重要な構造要素です。ランキングに直接影響を与えるものではありませんが、Googleがページのコンテンツをより理解するのに役立ちます。
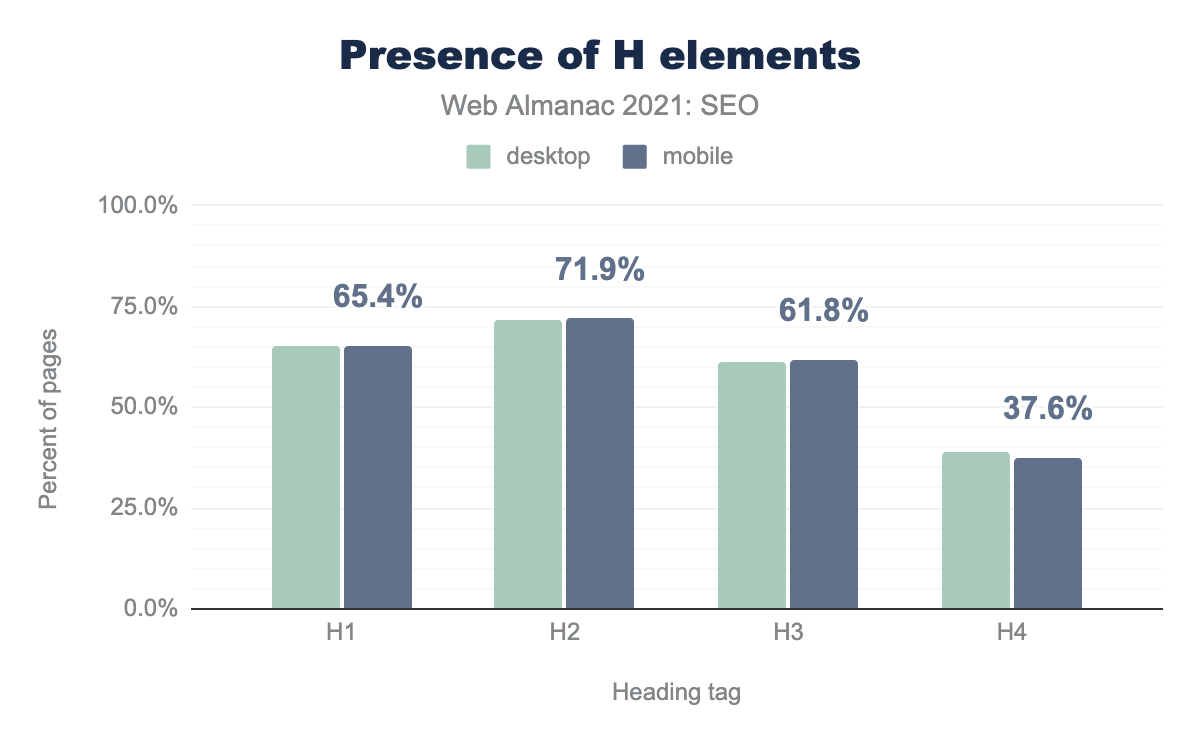
h1の見出しは65.4%のページに、h2は71.9%のページにもっとも多く、h33は61.8%のページに、h4の見出しは37.6%のページに見受けられた。主な見出しについては、 h1(65.4%)よりも多くのページ(71.9%)にh2があります。この差に明確な説明はありません。デスクトップとモバイルのページの61.4%は h3 を使い、h4 は39%以下です。
デスクトップとモバイルの見出しの使い方にほとんど差はなく、2020年に対して大きな変化もありませんでした。
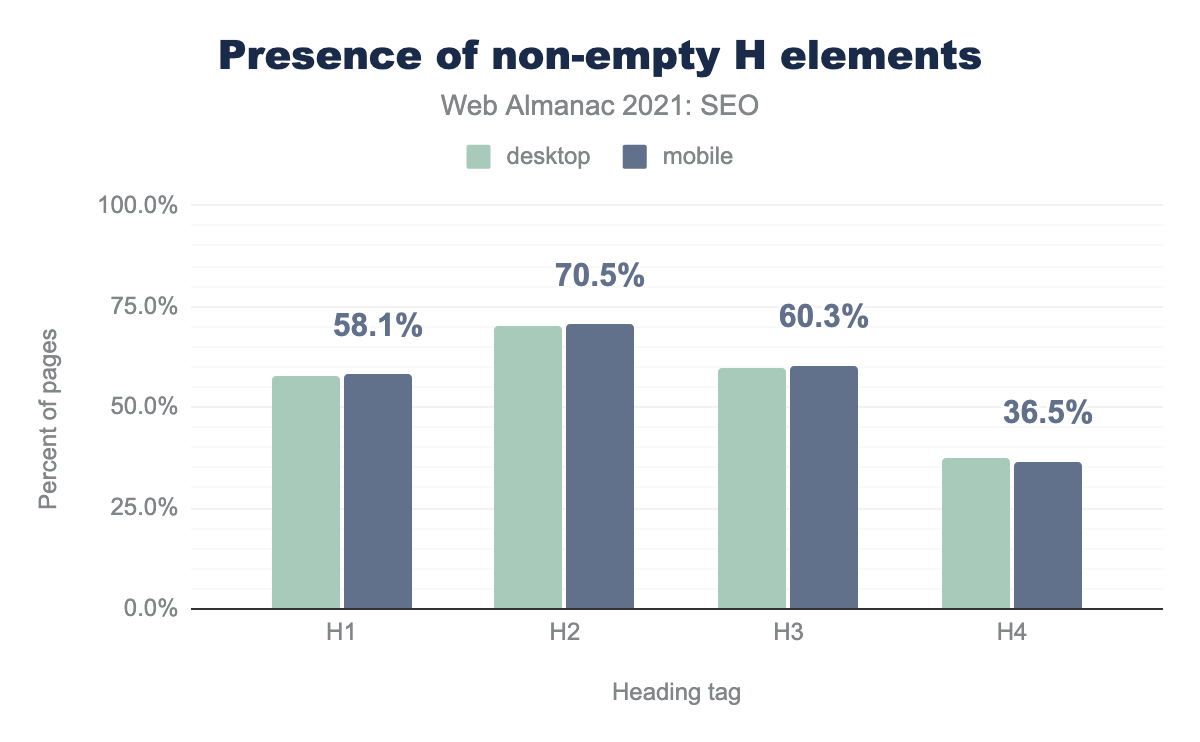
<h>要素が存在するページの割合を示した棒グラフです。デスクトップとモバイルの結果には、ほとんど差がありませんでした。h1の見出しは58.1%のページで、h2は70.5%のページで、h3は60.3%のページで、h4の見出しは36.5%のページで、それぞれもっとも多く見受けられました。しかし、空ではない<h>要素、とくにh1を含むページの割合は低くなっています。ホームページでは、ロゴ画像を<h1>要素で囲むことが多いので、このような結果になったのでしょう。
リンク
検索エンジンは、リンクを利用して新しいページを発見し、ページの重要性を判断するのに役立つページランクを渡すために使用しています。
ページランクに加え、リンクアンカーとして使用されるテキストは、検索エンジンがリンク先のページが何であるかを理解するのに役立ちます。Lighthouseでは、使用されているアンカーテキストが有用なテキストであるか、それとも「詳しくはこちら」や「ここをクリック」といったあまり説明的でない一般的なアンカーテキストであるかをチェックするテストが用意されています。テストしたリンクの16%は、説明的なアンカーテキストを持っていませんでした。これは、SEOの観点からは機会を逃し、またアクセシビリティの観点からも良くありません。
内部および外部リンク
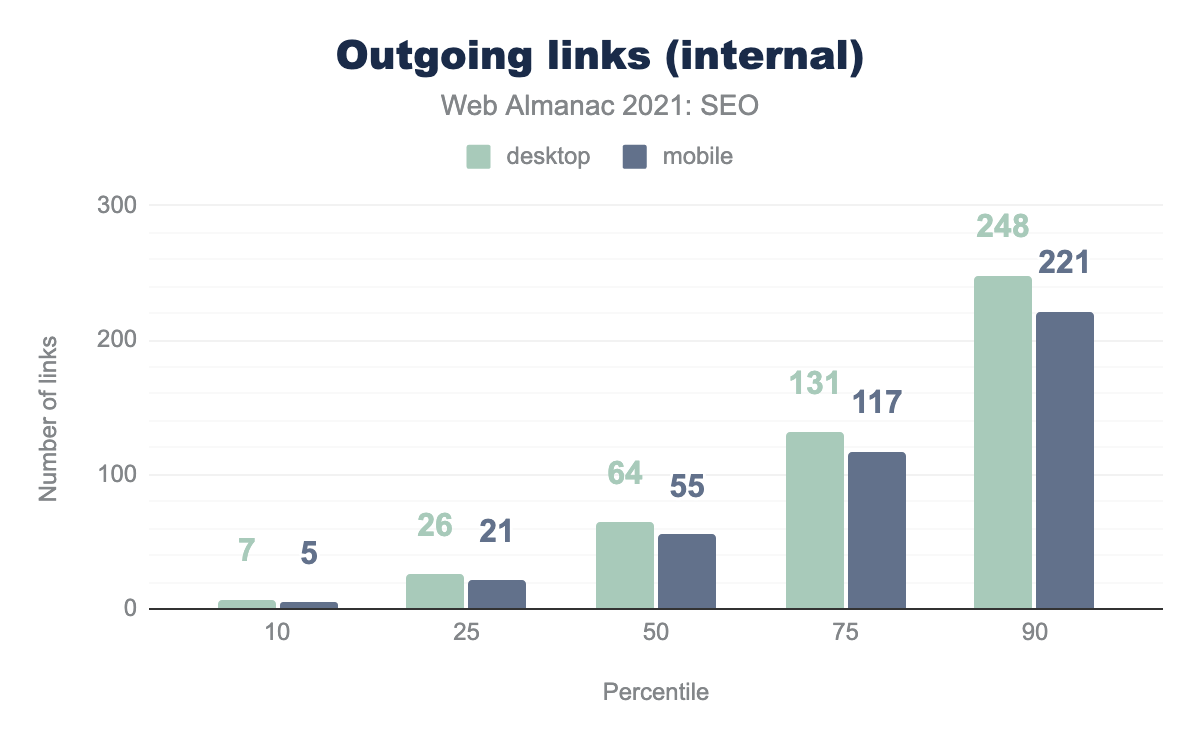
内部リンクとは、同じサイト内の他のページへのリンクのことです。デスクトップ版に比べ、モバイル版ではページのリンクが少なかった。
このデータによると、デスクトップの内部リンク数の中央値はモバイルよりも16%多く、それぞれ64対55となっています。これは、開発者が小さい画面でも使いやすいように、モバイルではナビゲーションメニューやフッターを最小限にする傾向があるためと思われます。
もっとも人気のあるウェブサイト(CrUXのデータによると上位1,000)は、人気のないウェブサイトよりも多くの発信内部リンクを持っています。デスクトップでは144、モバイルでは110で、中央値より2倍以上多いのです。これは、一般的にページ数の多い大規模なサイトでメガメニューが使用されているためと思われます。
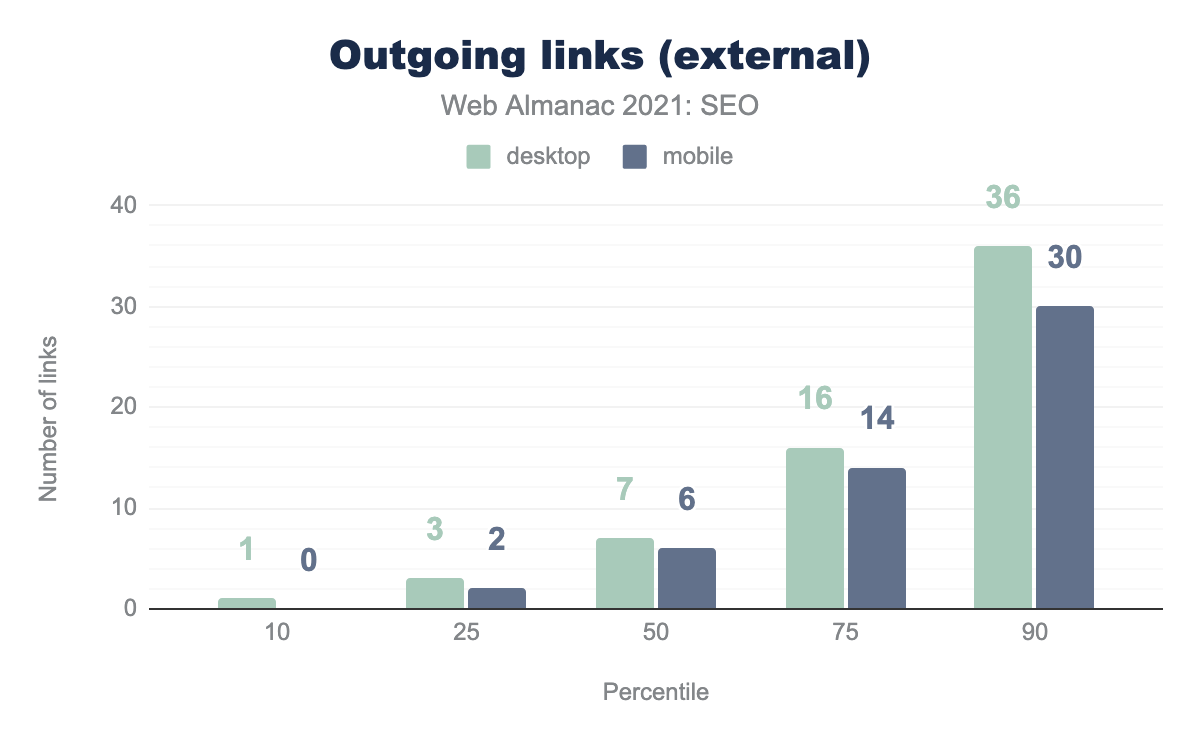
外部リンクとは、あるウェブサイトから別のサイトへのリンクのことです。このデータでも、モバイル版のページで外部リンクは少ないことがわかります。
2020年とほぼ同じ数字になっています。Googleは今年、モバイルファーストインデックスを展開したにもかかわらず、ウェブサイトはモバイル版をデスクトップ版と同等にすることができていないのです。
テキストと画像のリンク
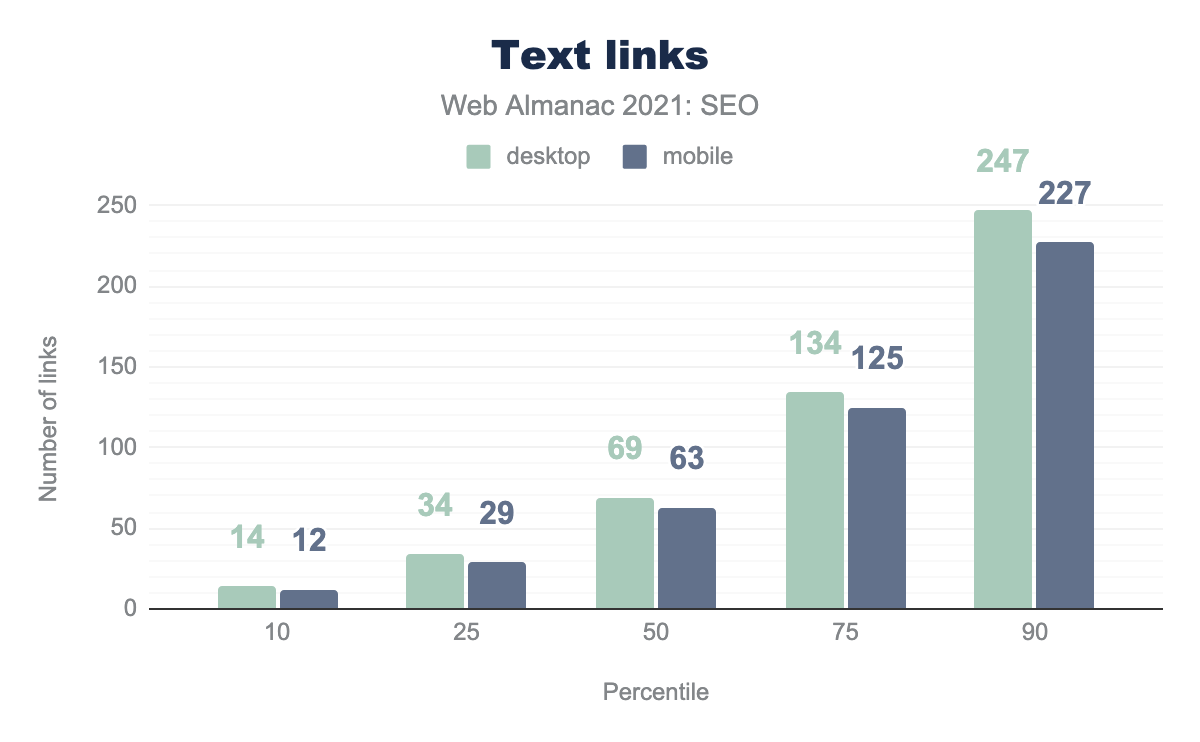
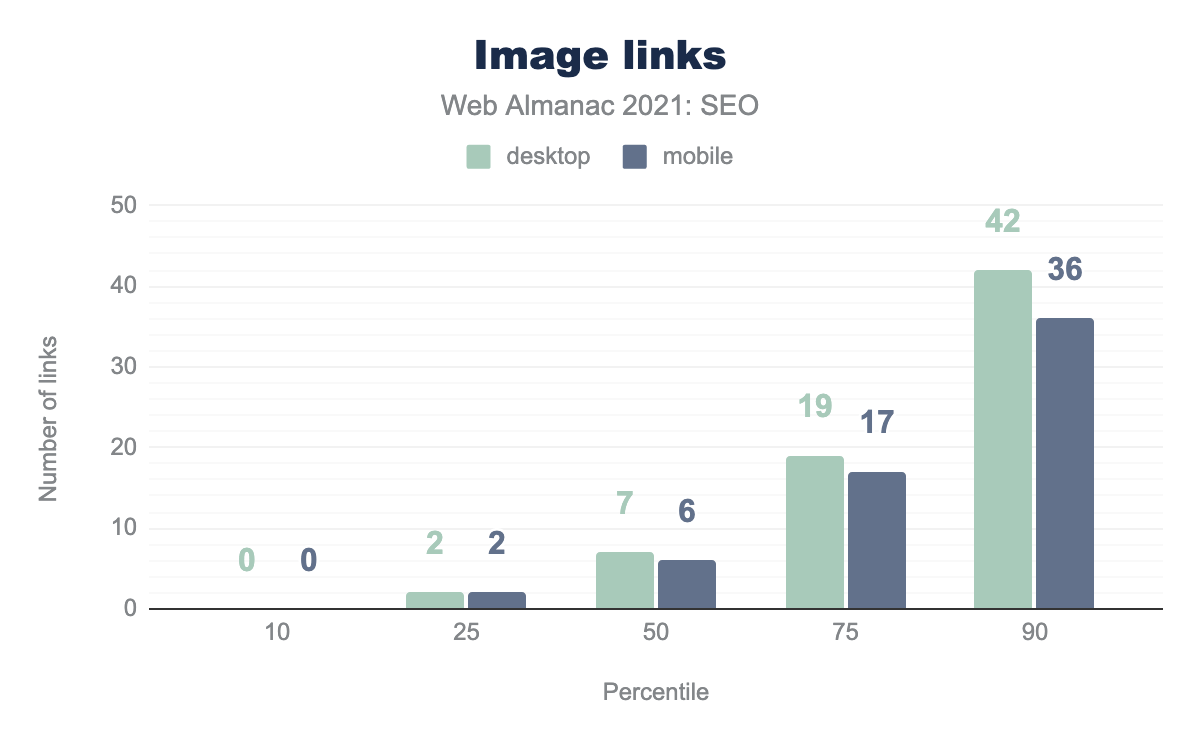
ウェブ上のリンクの大部分はテキストベースですが、画像から他のページにリンクしているものもあります。デスクトップページのリンクの9.2%、モバイルページのリンクの8.7%が画像リンクです。画像リンクでは、画像に設定された alt 属性がアンカーテキストとして機能し、そのページが何についてのページなのか、さらに詳しい情報を提供します。
リンク属性
2019年9月、Googleはリンクをスポンサーまたはユーザーが作成したコンテンツに分類できる属性を導入しました。これらの属性は、以前2005年に導入されたrel=nofollowを追加したものです。新しい属性である rel=ugc と rel=sponsored は、リンクに追加情報を与えます。
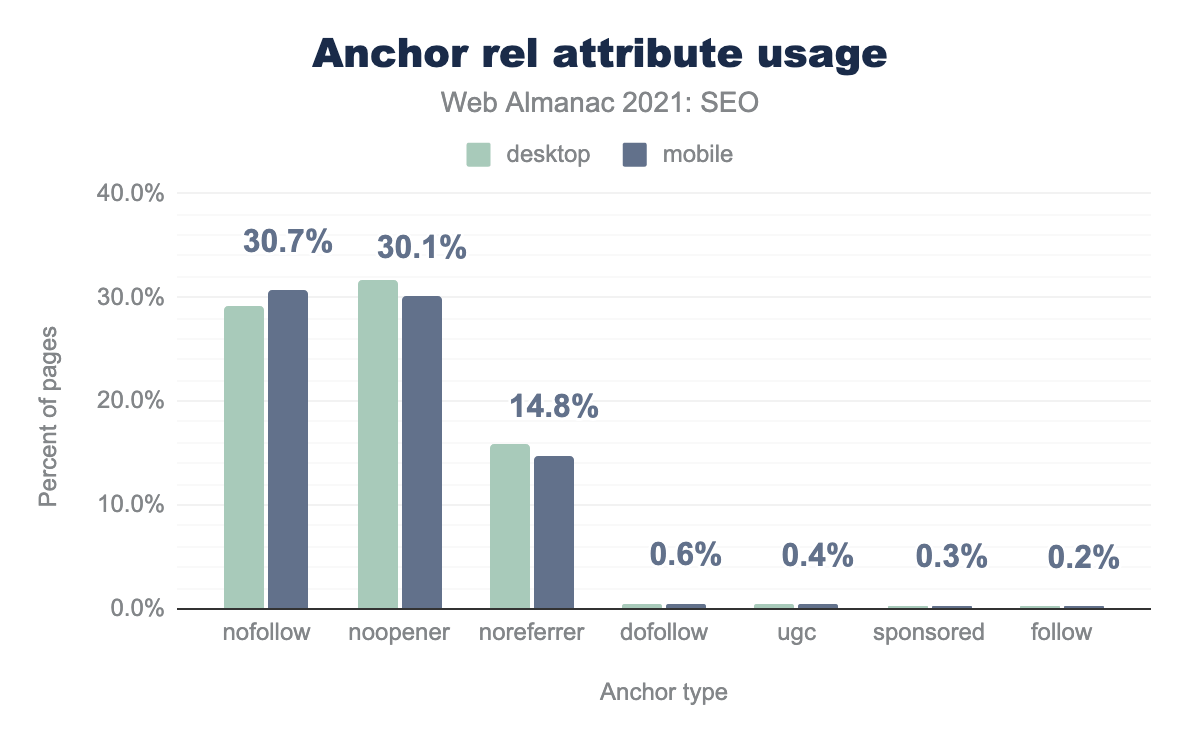
rel="noopener"は、デスクトップページの31.6%、モバイルページの30.1%で採用されました。rel="noreferrer"はデスクトップページの15.8%、モバイルページの14.8%に掲載されました。rel="dofollow"、rel="ugc"、rel="sponsored"、rel="follow"はいずれもデスクトップとモバイルのページの1%未満にしか表示されませんでした。新しい属性は、少なくともホームページではまだかなり稀で、rel="ugc"はモバイルページの0.4%、rel="sponsored"はモバイルページの0.3%に表示されます。これらの属性は、ホームページ以外のページでより多く採用されている可能性があります。
rel="follow" と rel=dofollow は rel="ugc" や rel="sponsored" よりも多くのページで表示されます。これは問題ではありませんが、Googleは rel="follow" と rel="dofollow" を公式の属性ではないので無視します。
rel="nofollow"は30.7%のモバイルページで見つかり、昨年と同様でした。この属性は非常に多く使われているため、Googleがnofollowをヒントに変更したのは当然のことで、つまり、それを尊重するかどうかを選択できるようになったのです。
アクセラレイテッド・モバイル・ページ(AMP)
2021年、アクセラレイテッド・モバイル・ページ (AMP)のエコシステムに大きな変化がありました。AMPは トップページカルーセルには必要なくなり、Google Newsアプリにも必要なくなり、GoogleはSERPのAMP結果の横にAMPロゴを表示しなくなりました。
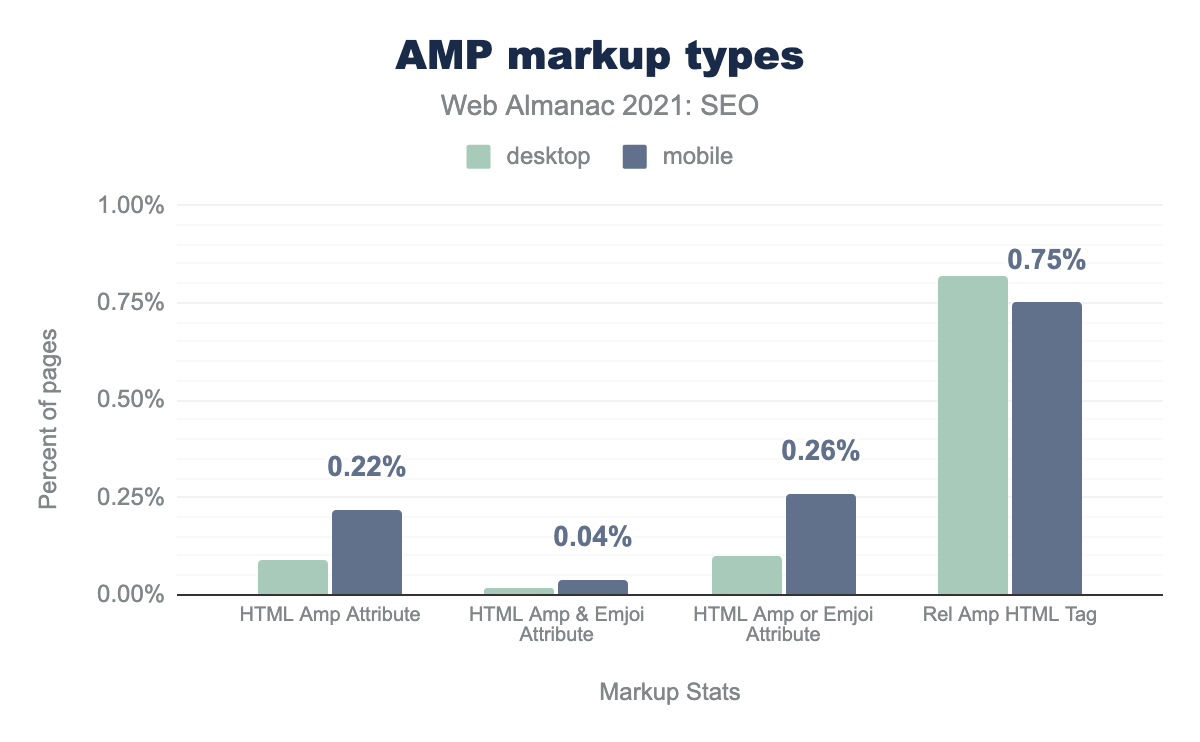
しかし、2021年になってもAMPの採用は増え続けている。現在、デスクトップページの0.09%にAMP属性が含まれているのに対し、モバイルページは0.22%となっています。これは、2020年のデスクトップページの0.06%、モバイルページの0.15%から上昇したものです。
国際化
言語や地域によって複数のバージョンのページがある場合は、Googleにそのことを伝えてください。そうすることで、Google検索がユーザーに言語や地域ごとにもっとも適切なバージョンのページを提供することができます。
検索エンジンにローカライズされたページを知らせるには、hreflangタグを使用します。hreflang属性は、Yandex やBing(ある程度)でも使用されています。
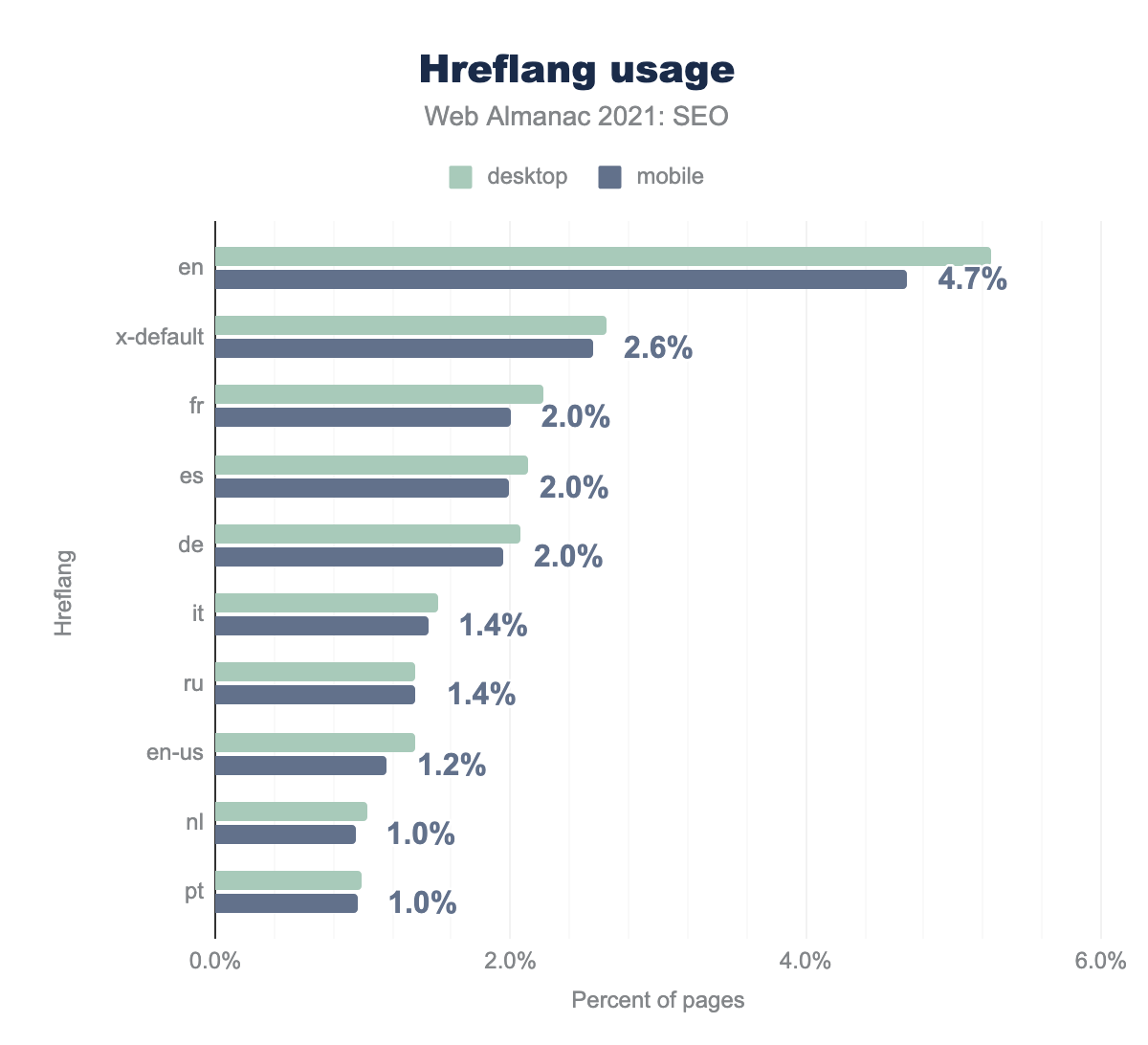
en(英語版)で、hreflang属性(全言語)はデスクトップおよびモバイルページの5%未満にしか実装されていませんでした。デスクトップ用ページの9.0%、モバイル用ページの8.4%がhreflang属性を使用しています。
hreflang 情報の実装方法には、HTMLの <head> 要素、 Link ヘッダー、XMLサイトマップの3つがあります。このデータには、XMLサイトマップのデータは含まれていない。
hreflang属性でもっとも利用されているのは、"en"(英語版)です。モバイル用ホームページの4.75%、デスクトップ用ホームページの5.32%が使用しています。
x-default(フォールバック版とも呼ばれる)は、モバイルでは2.56%のケースで使用されています。hreflang 属性で指定されるその他の一般的な言語は、フランス語とスペイン語です。
Bingにとって、hreflang は content-language ヘッダーよりも「はるかに弱い信号」です。
他の多くのSEOパラメーターと同様に、content-languageには、以下のような複数の実装方法があります。
- HTTPサーバーレスポンス
- HTMLタグ
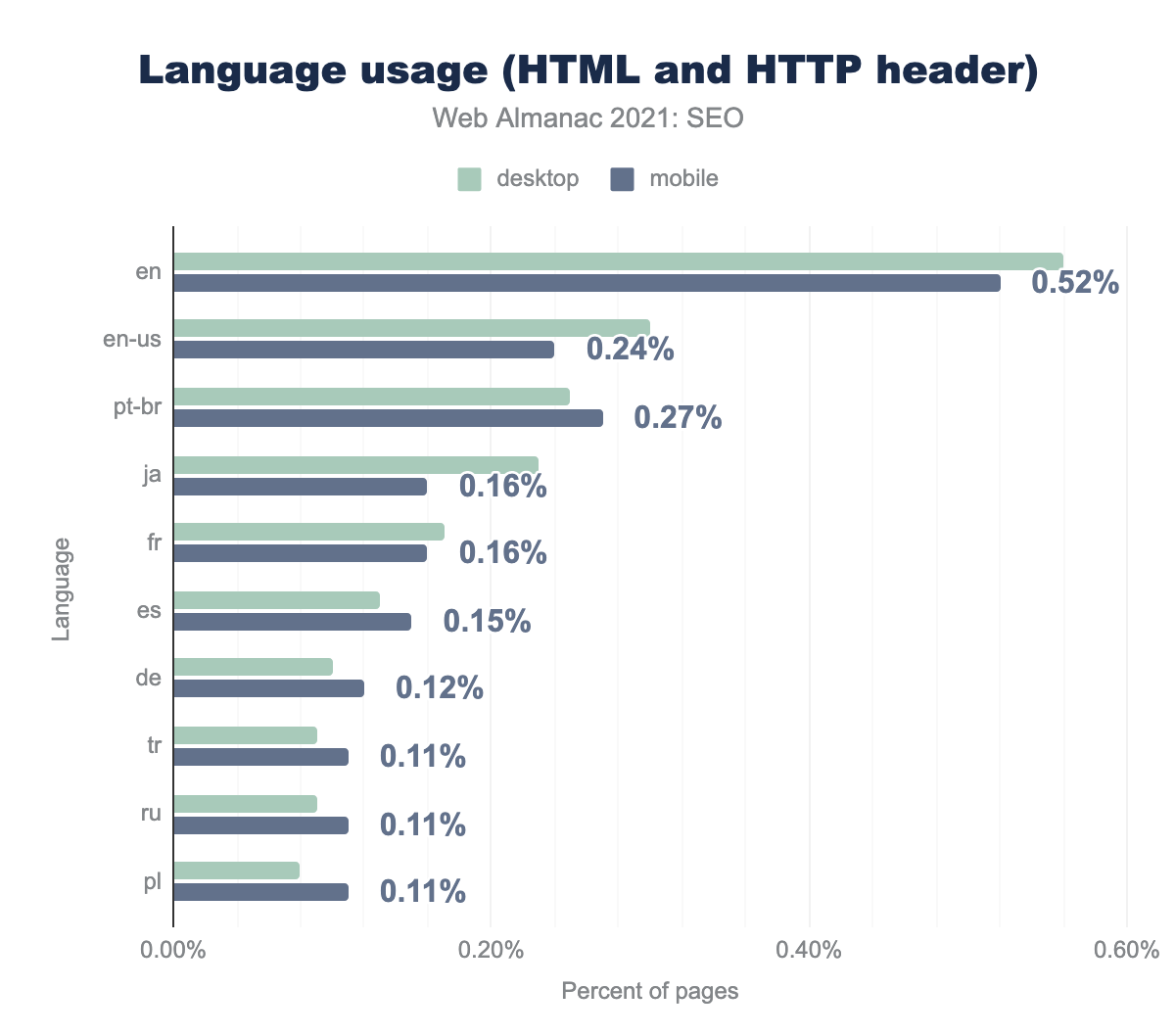
content-language を実装するには、HTTPサーバーレスポンスを使用するのがもっとも一般的な方法です。デスクトップでは8.7%、モバイルでは9.3%のウェブサイトがこの方法を採用しています。
HTMLタグの使用はあまり一般的でなく、content-languageが表示されるのはモバイルサイトのわずか3.3%です。
結論
ウェブサイトは、SEOの観点から徐々に改善されてきています。おそらく、ウェブサイトがSEOを改善し、ウェブサイトをホストするプラットフォームも改善していることが複合的に作用しているのだろう。ウェブは広くて厄介な場所なので、まだまだやるべきことはたくさんありますが、一貫した進歩が見られるのは嬉しいことです。


